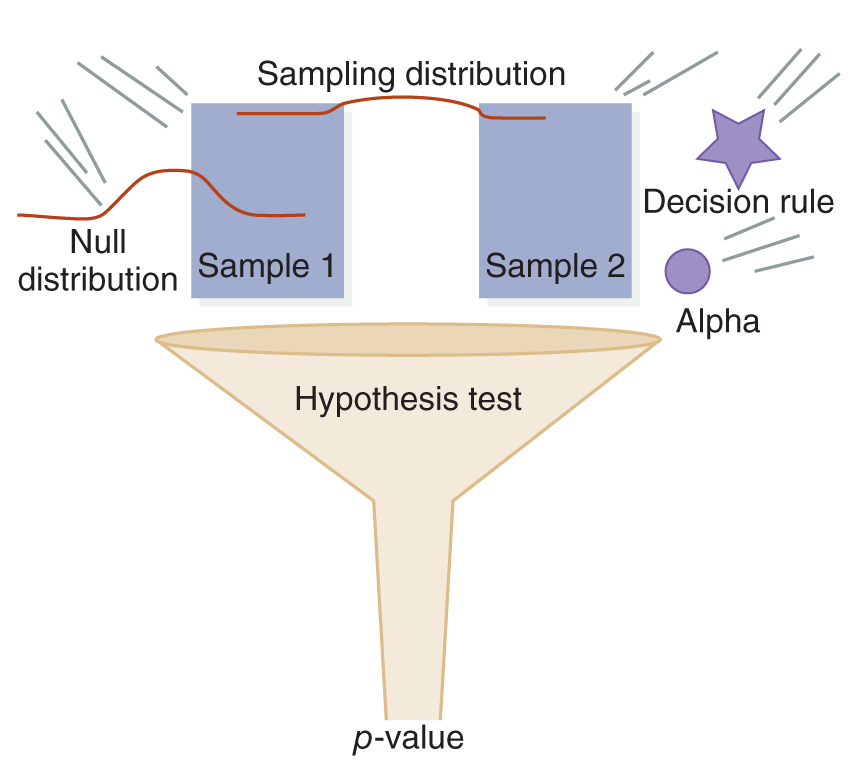
Statistical significance means that the difference you observe between two samples is large enough to conclude that it is not simply due to chance. Statistical significance can be shown in many different ways, but the basic idea remains the same: if you take two or more representative samples from the same population, and there really is a difference between the variables in this population, you would expect to find approximately the same difference again and again. If you have a statistically significant result, you can reject the null hypothesis.
But how do you know whether your result is statistically significant? At the beginning of the study, the researcher selects the significance level, or alpha, which is usually 0.05. This number is simply the probability assigned to incorrectly rejecting the null hypothesis or making what is called a type I error. For example, you conduct a study examining the association between eating a high-fiber breakfast and 10:00 AM serum glucose levels. The null hypothesis is that a high-fiber breakfast is not associated with the 10:00 AM serum glucose levels. The alternative is that it is. You select an alpha of 0.05. This means you are willing to accept that there is a 5% chance that you will reject the null hypothesis incorrectly. If you did so, you would report that eating a high-fiber breakfast is associated with a change in blood sugar levels at 10:00 AM when, in actuality, it is not.
Therefore, the alpha is the preestablished limit on the chance the researcher is willing to take that they will report a statistically significant difference that does not exist. The researcher is willing to say that a statistically significant difference exists right up until the point when the probability of being incorrect is about 5% (alpha = 0.05). An alpha of 0.05 can also be interpreted to mean that the researcher is 95% sure that the significant difference that they are reporting is correct.
Think about this in terms of waking a provider in the middle of the night. You are willing to do that if you are 95% sure your patient has an immediate concern, but you are not so willing to do that if you are only 15% sure that your patient has a pressing issue. The ramifications of being wrong can be substantial at 3:00 AM, no matter what you decide. You may make the call or continue to gather more observations until you are more confident. Remember, all statistical test results are reported as probabilities. No one is absolutely certain that they are correct!
Corresponding to the alpha (which is represented by α) is what statisticians call the p-value. Remember that we started to talk about this concept in Chapter 3. The p-value is the probability of observing a value of a test statistic if the null hypothesis (there is no relationship, association, or difference between the variables) is true. In other words, a p-value tells you the probability of finding your results and the corresponding test statistic if there is no relationship between the variables. This value is also the probability that an observed relationship, association, or difference is due simply to chance. For example, let’s say your study examining the consumption of a high-fiber breakfast and 10:00 AM glucose levels has a test statistic with a p-value of 0.03. Then the probability that the observations in your study would occur if there were no relationship between these variables (or by chance) is only 3%. This result means that you are 97% sure the variables in your study do have a relationship.
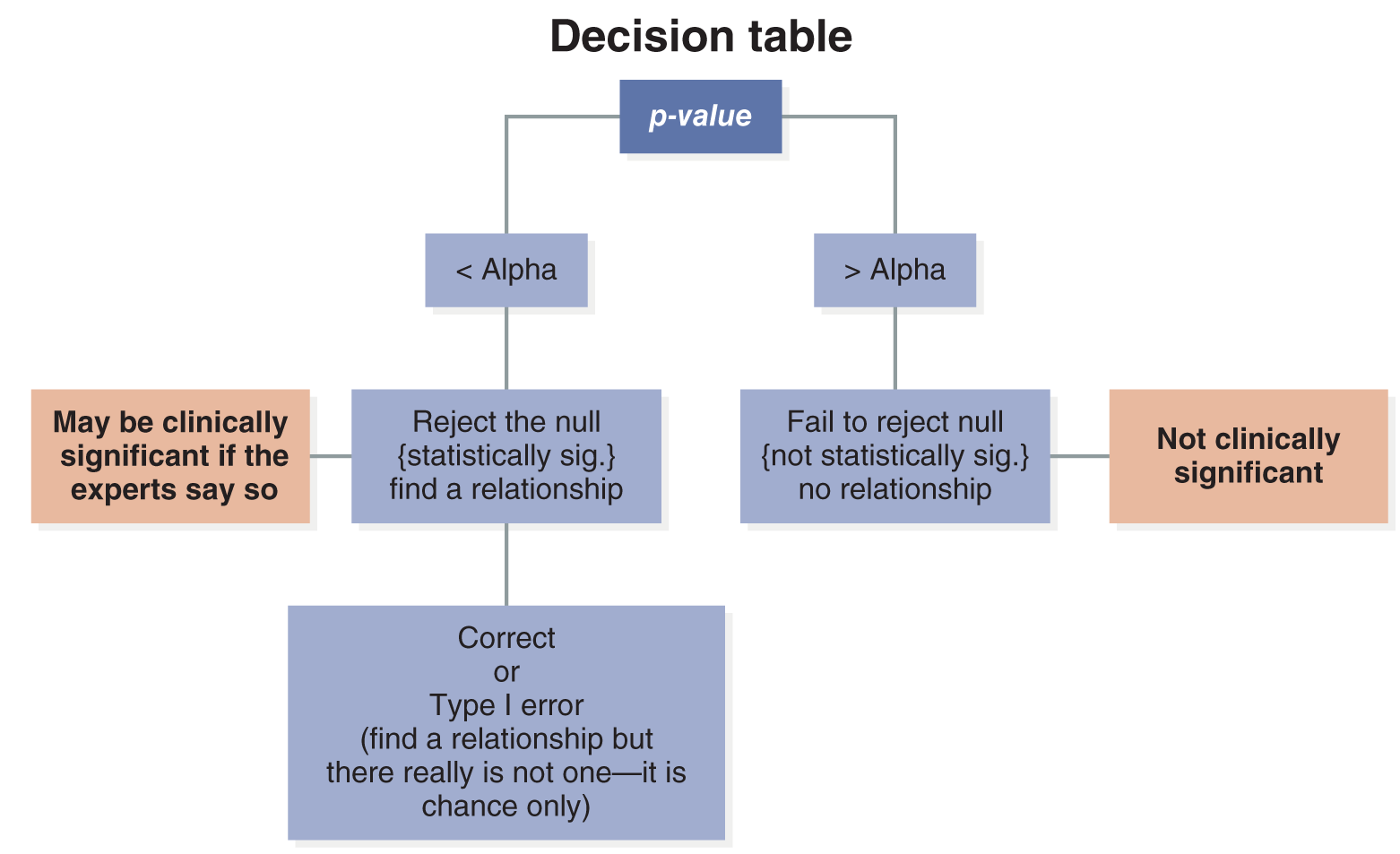
If your study has an alpha of 0.05, it means you are willing to accept up to a 5% chance of making a type I error and reporting that a relationship exists when it is just by chance. Suppose the actual p-value of your test statistic shows you have only a 3% chance of making a type I error (p = 0.03). In that case, you are within error limits that are comfortable for you (5% or less) and can confidently reject the null hypothesis. Rejecting the null hypothesis means reporting a relationship, an association, or a difference between the variables.
So now you know that if the p-value is less than the alpha, you should reject the null hypothesis. However, if the p-value is greater than the alpha, the chance of making a type I error is greater than the level you are comfortable with, and you should fail to reject the null hypothesis. In this case (p > alpha), you would fail to reject the null hypothesis and report that there is no relationship, association, or difference between the variables.
Subtracting the p-value from 1 tells you how sure the researcher is about rejecting the null hypothesis based on the data in that particular study. For example, a p-value of 0.03 means the researcher is 97% sure that the observed relationship is not just due to chance. Sometimes thinking of it this way helps.
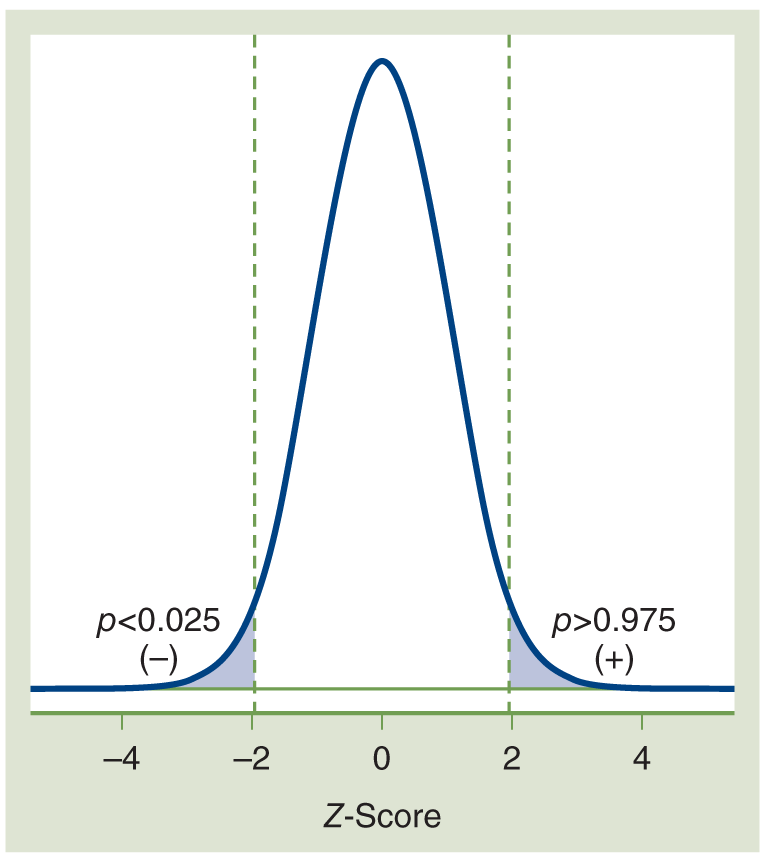
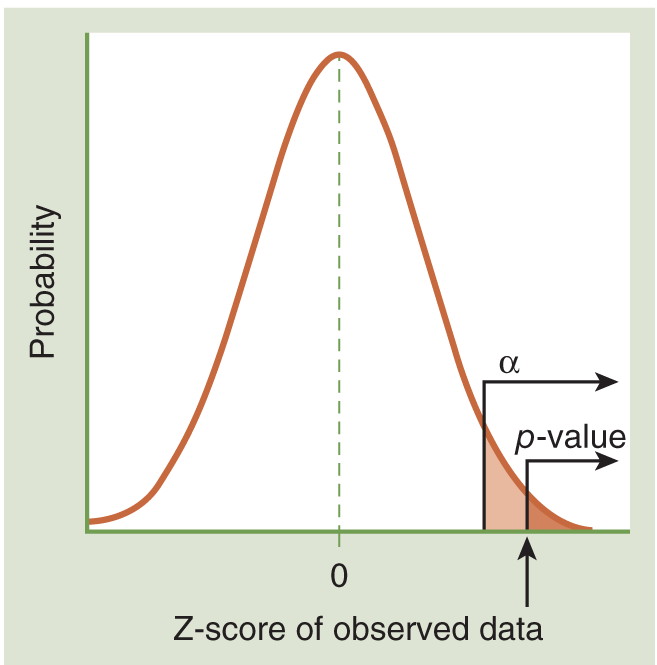
You can see how this looks on the probability distribution in Figure 6-1. A low p-value is way out in the tail of the probability distribution. If it is smaller than your alpha value, then the probability of finding this test result if the null hypothesis is true is smaller than the chance you are willing to take of being incorrect about rejecting the null. This is a graphic illustration of p< alpha, which means you have statistically significant results and should reject the null hypothesis.
From the Statistician
Brendan Heavey
Alpha of 0.05: Standard Convention Versus Experiment Specific
Interpreting p-values can be a science in and of itself. Let me share with you how I think of p-values.
Think about your favorite courtroom drama. Whether you recall O. J. Simpson’s trial, A Few Good Men, To Kill a Mockingbird, or Erin Brockovich, the defendants are innocent until proven guilty in all these situations. Therefore, the null hypothesis in these “experiments” is that the defendant is innocent. At all these trials, a defendant is declared not guilty, never innocent. The trial is being conducted—like an experiment—to determine whether to reject the null hypothesis. The null hypothesis cannot be proven; it can only be disproven.
In O. J.’s case, a lot of people thought there was enough evidence to reject the null hypothesis of innocence and find him guilty. However, as in any criminal case, O. J. had to be declared guilty beyond a reasonable doubt. This is a very stringent criterion. Later, in the civil case, the district attorney only had to show a preponderance of evidence to have him declared liable, which was a much easier task. So O. J. was found not guilty in the criminal trial but liable in the civil trial. This split decision is the equivalent of different alpha levels determining statistical significance in statistical experiments. The courts reduced the stringency of the test from determining criminal guilt to civil liability by reducing the burden of proof necessary to reject the null hypothesis between the two tests. Scientists can do the same thing in statistical tests by increasing alpha (which “decreases the burden of proof” in your study). Notice that showing a defendant is liable in a civil trial (because of a preponderance of evidence) is easier to do than showing the defendant is guilty in a criminal trial (beyond a reasonable doubt). Think of a statistical test the same way. If your p-value is 0.07, you would reject the null hypothesis if your alpha is 0.10 (less stringent) but not if your alpha is 0.05 (more stringent). It is easier to reject the null hypothesis at the 0.10 level than the 0.05 level.
Note that 0.05 is a very arbitrary alpha cutoff. It has persisted to this day only because R. A. Fisher preferred it, and he’s one of the most important statisticians and scientists of all time. He started the practice back in the 1920s, and it has stuck ever since. However, at times, scientists use a more stringent cutoff of 0.01 or a less stringent one of 0.1. Determining statistical significance is a sliding scale, just like the sliding scale of burden of proof in the courtroom.
I would like to thank Jeffrey J. Isaacson, J. D., Professor at Emmanuel College, for taking the time to clarify the terminology utilized in civil trial procedures.