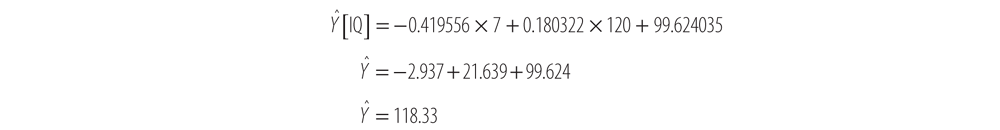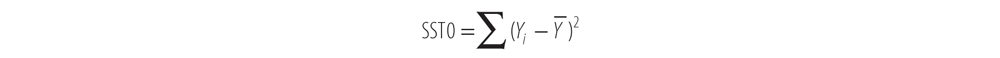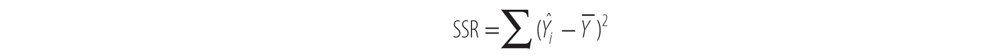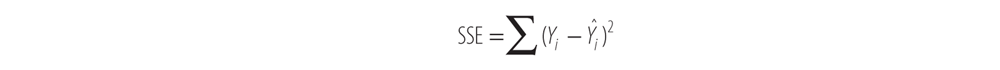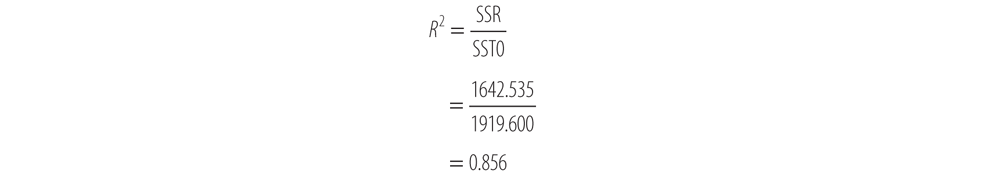It is one thing to recognize statistically significant relationships and another to be able to use that information to begin the process of inferring or predicting future events. In order to do that, we first need to quantify the association. Let’s look at an example. Most obstetric nurses have read the literature showing a significant relationship between smoking and fetal weight. This is helpful knowledge to have for our pregnant patients. However, if you have a patient who is smoking 10 cigarettes a day and really doesn’t want to quit, she may not think smoking 10 cigarettes a day will have that much of an impact on the size of her baby. Just being able to tell her there is a statistically significant correlation between smoking and fetal weight may not be enough. You are going to need to use more statistics before you can convince this patient that it is important for her to quit smoking.
You know that correlations measure the strength of associations; now we want to be able to quantify that association, which involves one of my favorite statistical techniques, called regression. No, we are not all going to take a moment and relive childhood memories. This is math, remember, but it can still be fun! Regression happens to be a favorite test of mine for one basic reason: developing an accurate regression equation is the first step in being able to predict future events. It is like being a psychic—but this time your predictions should actually be true!
Of course, there isn’t just one kind of regression analysis, so let’s start with the most basic, although not one that is used that often in the literature. You need to understand the basics of linear regression before you understand the more complex types of regression, so it is a good place to begin.
Linear regression looks for a relationship between a single independent variable and a single interval- or ratio-level dependent variable. (You can sometimes use this technique when you have ordinal-level dependent variables as well, but it gets a little more complicated.) Once the temporality of the relationship is established, you can then make an inference or a prediction about the future value of the dependent variable at a given level of the independent variable. In the fetal weight example, you might use linear regression to see the relationship between the number of cigarettes smoked each day and fetal weight. Maybe knowing, for example, that for every five cigarettes a day a patient doesn’t smoke, her baby will weigh about a half a pound more will help motivate your pregnant patient to decrease her cigarette smoking.
From the Statistician
Brendan Heavey
Statistics, Jerry Springer Style: Now Let’s Look at Some Relationships That Aren’t Functional!
Regression is a method that allows us to examine the relationship between two or more variables. You may recall another way of exploring the relationship between two variables from earlier in life when you first learned to graph a line using the formula Y = mX + b. Remember what all these letters represent:
Y is the dependent variable and is displayed on the vertical axis.
X is the independent variable and is displayed on the horizontal axis.
M is the slope and represents the amount of change in the Y variable for each unit change in the X variable.
b is the Y-intercept, and it tells us the value of Y when the line crosses the vertical axis (X = 0).
In this relationship, the value of the variable Y varies according to the value of X based on the values of two constants, or parameters. If you know the values of m, X, and b, you can solve for the value of Y exactly. Let’s look at an example. In the graph shown in Figure 12-1, you can see three functional relationships between the total cost of three different types of treatment for minor wound infections in June. Treatment 1, outpatient treatment, is cheaper per unit, so there is a more gradual rise in overall cost for each additional treated case. Because all three treatments pass through the origin, their Y-intercepts are all 0. In fact, the only differences between these three lines are their slopes. Their equations are:
Figure 12-1: Relationship Between Total Cost and Number of Patients Treated (Functional Relationship).
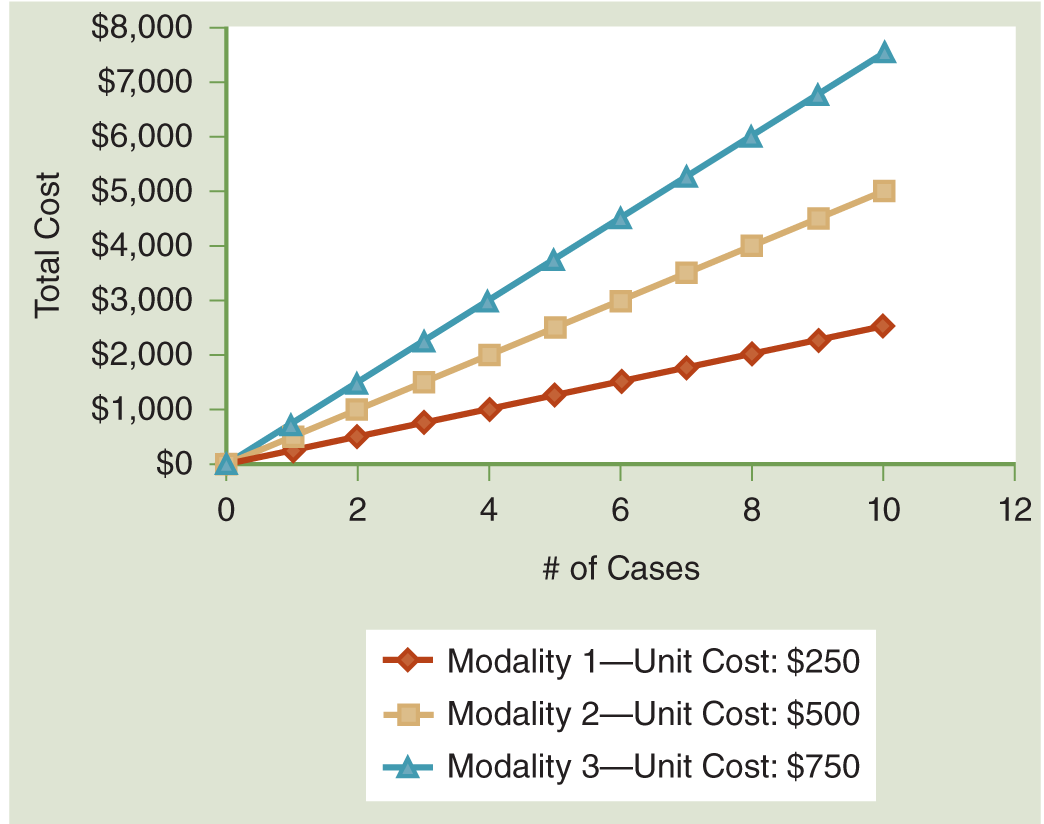
Treatment 1 (outpatient)—$250/case: Y = 250 X
Treatment 2 (inpatient medical treatment)—$500/case: Y = 500 X
Treatment 3 (same-day surgical treatment)—$750/case: Y = 750 X
This math is all well and good, but things rarely work out this nicely in nature. The problem that usually occurs is that the relationship between most variables, just like the relationship between many people, is not functional. Can you guess what term best describes the relationship between almost all variables? Why, statistical, of course! You see, the difference between a functional relationship and a statistical relationship is that a statistical relationship accounts for error.
As it turns out, accounting for error is a very difficult task. We rarely, if ever, know how error is distributed around a mean value, so we usually have to make a few assumptions to allow us to make sense of our data.
In this text, we are doing our best to keep things simple and give you a basic introduction to regression, so we will stick with one of the most basic regression models available, namely, the normal error regression model. In this model, our most basic assumption is that the error we model is normally distributed around the mean of Y. This is okay to do, especially as our sample size is increased. Do you remember why? It is because of the central limit theorem. Because the distribution of the sum of random variables approaches normal as the number of variables is increased, and as our sample size increases, the amount of random error increases, we can assume that the distribution of this random error approaches normality. It is okay to make this assumption as long as you have a large enough sample. It is important to note that a few other assumptions are used in the normal error regression model, but they are beyond the scope of this text and most aspects of life.
So now let’s look at what a statistical relationship or statistical model looks like. Here is the definition of the normal error regression model:
Yi = β0 + β1Xi + εi
In this model, there are three variables and two parameters (one more than the functional model you just saw). Here is what each of these terms means:
Yi: The value of the dependent variable in the ith observation
Xi: The value of the independent variable in the ith observation
εi: The normally distributed error variable
β0 and β1 are parameters, just like the slope, m, and the Y-intercept (b) were in the functional relationship earlier.
Let’s say we now have a little more information on treatment 1 (outpatient management) from our previous example. In this case, although there was an exact functional relationship between the number of cases and total cost, when we look at the relationship between unit cost and time, it looks like this:
Cost of Treatment 1 Throughout the Year | |
|---|---|
January | $118 |
February | $150 |
March | $165 |
April | $205 |
May | $215 |
June | $253 |
July | $276 |
August | $289 |
September | $310 |
October | $325 |
November | $332 |
December | $362 |
Average | $250 |
There is not an exact functional relationship. In fact, the unit cost is increasing over time, but the amount of each increase is different each month. The increase in cost per month varies according to a few different factors, but you can see that if we graph these data, the trendline shows that unit cost is increasing, on average, by $21.72 per month (see Figure 12-2).
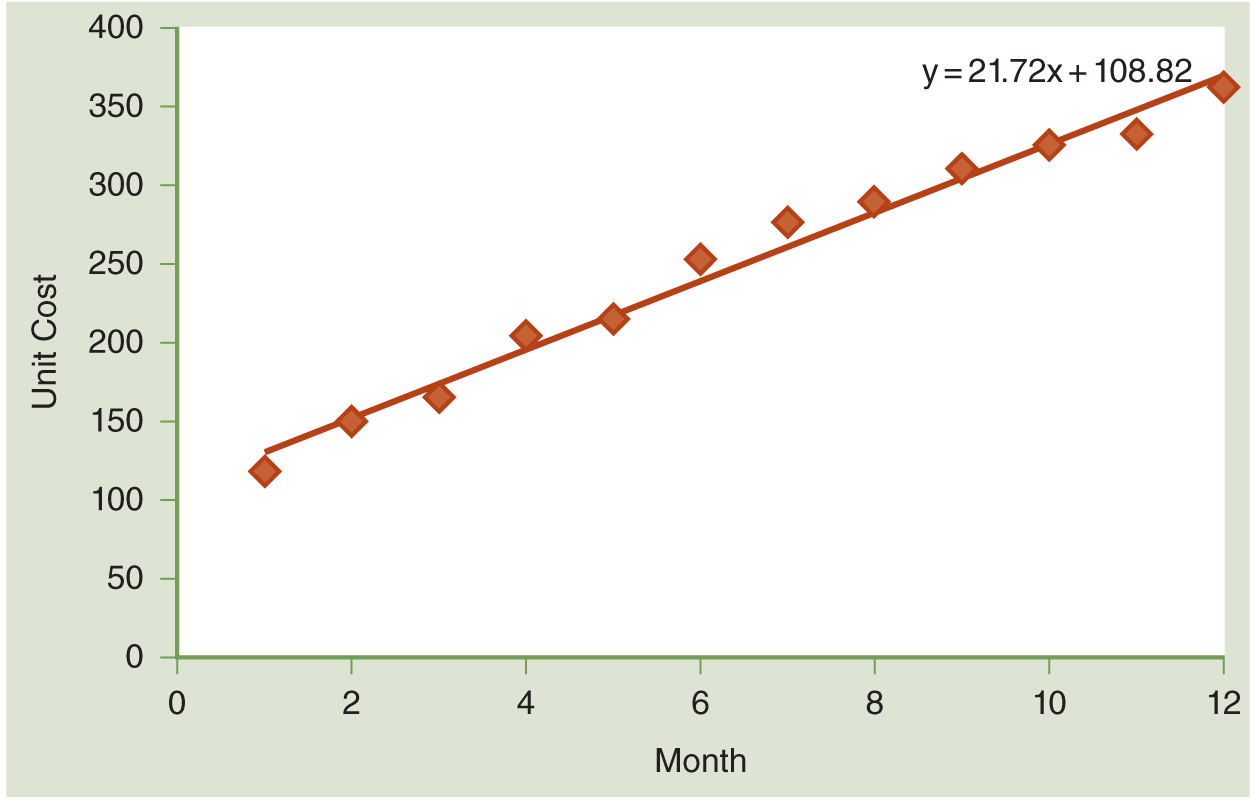
Notice that you can see the error in this relationship. The trendline shows you a functional relationship that is buried inside the statistical relationship. The functional relationship is exactly quantified by two parameters and two variables:
Y = 21.72 X + 108.82
The statistical relationship adds a third variable (error, ε), which allows the points on the graph the freedom to vary around this functional relationship because statistical relationships are never exact:
Y = 21.72 X + 108.82 + ε
Linear regression plots out the values of the dependent variable (i.e., fetal weight) on the y-axis and the values of the independent variable (i.e., daily number of cigarettes) on the x-axis to find the line to illustrate the relationship between the two variables best (see Figure 12-3).
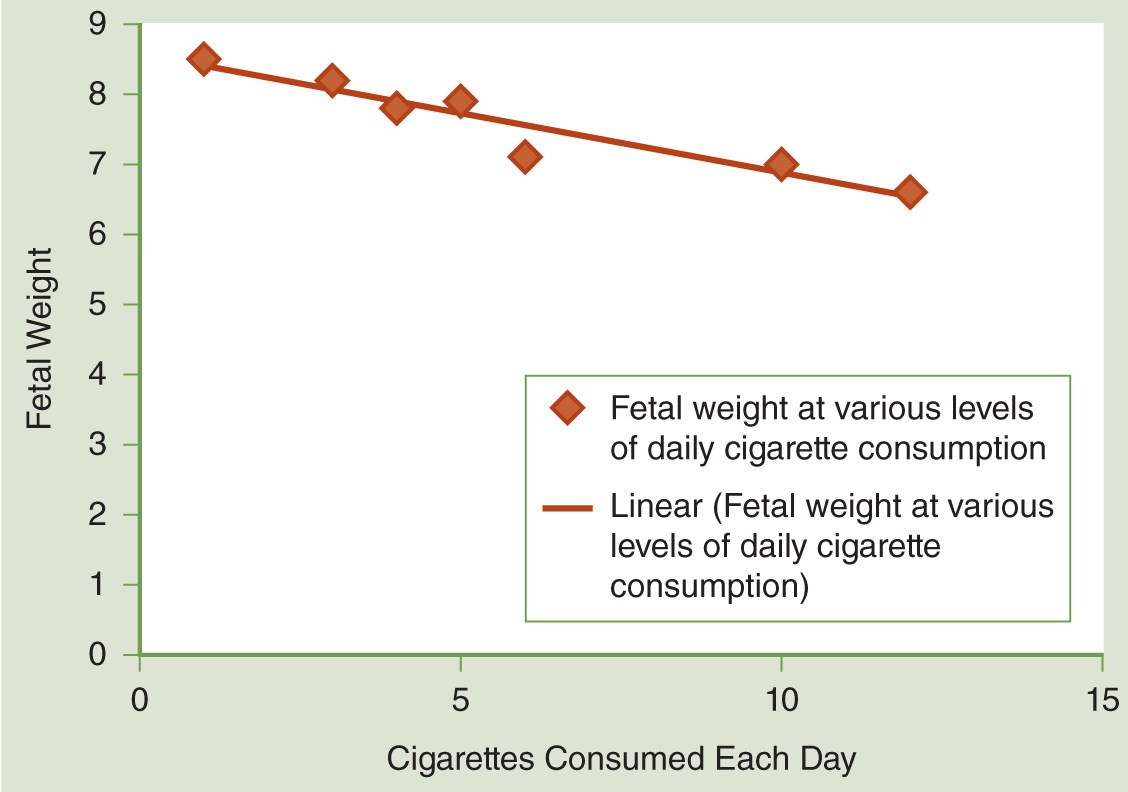
Assuming there is a linear relationship (you can see how a trendline is not exactly on the points of data, but the points follow it pretty closely or in a linear fashion), this line can then be used to make predictions about the future value of the dependent variable at the different levels of the independent variable. The difference between where the points of data actually fall and where the line predicts they will fall is something called a residual, or the prediction error, which is discussed further in the next “From the Statistician” feature. The lower the amount of residual, the better the line fits the actual data points.
The slope of the trendline tells how much the predicted value of the dependent variable changes when there is a one-unit change in the independent variable. In our example, the slope of the line would tell us how much the predicted fetal weight would drop with the consumption of an additional cigarette each day. Seems simple enough, right?
Unfortunately, life is rarely so simple, and statistics has to keep up with it. (And you thought statistics was what made life complicated!) Very rarely is there only one independent variable we need to consider, which may leave you asking: What do you do when you want to predict how two or more variables will affect the dependent or outcome variable? For example, the length of the pregnancy and the number of cigarettes smoked each day both affect fetal weight. You would not want to predict fetal weight with just one of these independent variables; you would want to include both. How can you make an accurate prediction in this situation? (No, no, don’t use the crystal ball. . . .) You just need to use another statistical test called multiple regression.
So let’s go back to the example of studying fetal weight. Multiple regression lets us take the data we have measuring months pregnant (independent variable number 1 or X1) and the number of cigarettes smoked (independent variable number 2 or X2) and see how these variables relate and affect the outcome, which is fetal weight (dependent variable or Y). Using this example, the relationship can be expressed in an equation like this:
Yi = a + b1X1 + b2X2 + e
Now I know many of you just looked at this equation and started to think, what on earth does this equation mean? Don’t panic. Let’s break it apart.
Yi is just the value of your dependent variable, in this case, how much the fetus weighs.
The value of a is what is called the constant, or the value of Y when the value of X is 0. In our example, this would be the value of Y or fetal weight when the patient is not yet 1 month pregnant and has not smoked any cigarettes. Obviously, there would still be some fetal weight, although in this example, a is probably going to be a very small number.
b1 is the value of the regression coefficient for our first independent variable. It is the rate of change in the outcome for every one-unit increase in the first independent variable. In our example, it is how much we would expect fetal weight to increase for each additional month of pregnancy.
X1 is the value of our first independent variable, or, in this example, how many months pregnant the patient is at the time of measurement.
b2 is the value of the regression coefficient for the second independent variable. It is the rate of change in the outcome for every one-unit increase in the second independent variable. In our example, it is how much change we would expect in fetal weight when one additional cigarette is smoked every day. In all likelihood, the value of b2 would be negative in this example because increases in daily cigarette consumption usually lower fetal weight. If the value of the regression coefficient is negative, an increase in the corresponding independent variable produces a decrease in the dependent or outcome variable, such as an increase in cigarette consumption producing a decrease in fetal weight.
From the Statistician
Brendan Heavey
What Is a Residual?
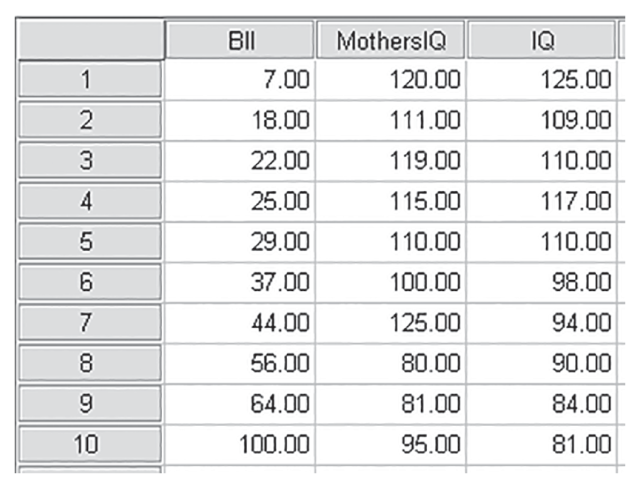
Consider the following data, which show the results of a survey that collected IQ levels for a series of patients with elevated blood lead levels (BLLs):
Obs. | BLL (mcg/dL) | IQ |
|---|---|---|
1 | 7 | 125 |
2 | 18 | 109 |
3 | 22 | 110 |
4 | 25 | 117 |
5 | 29 | 110 |
6 | 37 | 98 |
7 | 44 | 94 |
8 | 56 | 90 |
9 | 64 | 84 |
10 | 100 | 81 |
Now, you can see in Figure 12-4 what these data look like when we graph them. Let’s look at this model a little more in depth. To do so, we’ll need two definitions:
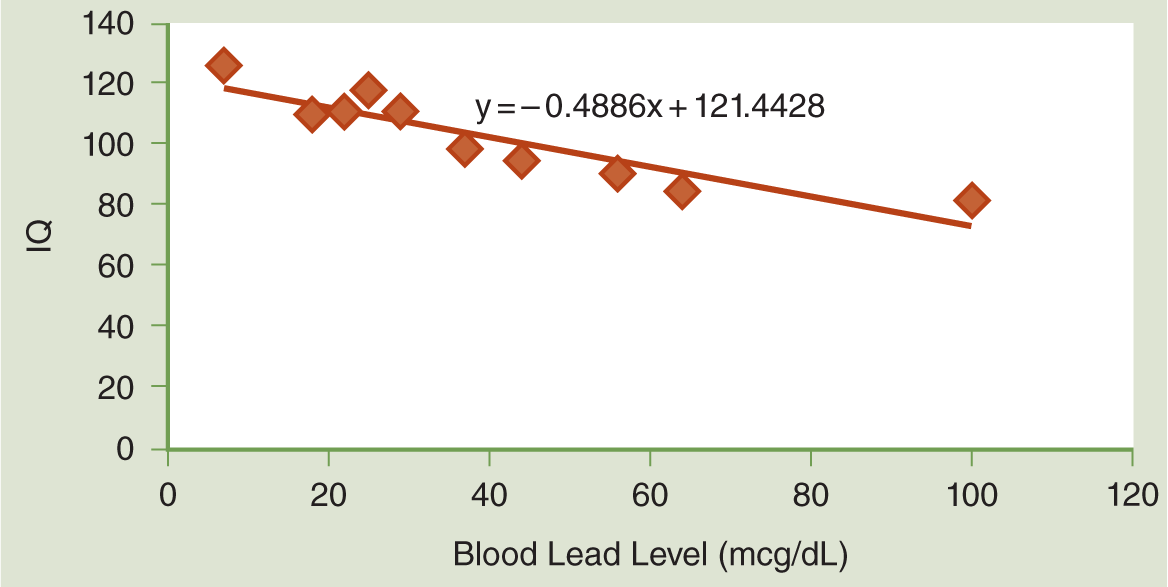
- We refer to the fitted value of our regression function (or the inferred value of the dependent variable) at a particular X value as Ŷ(pronounced Y-hat). Because the formula for our regression line is Ŷ= -0.4886 X + 121.4428, if we are interested in the fitted value at an X of 7, we solve for Ŷlike this:
Ŷ= -0.4886(7) + 121.4428
Ŷ= -3.4202 + 121.4428
= 118.0226
This means that at a BLL of 7, our regression model infers an IQ of 118.0226 on the y-axis.
- We refer to the distance between the actual observed value and the regression line as a residual, which is usually labeled using the Greek symbol ε. On a graph, it looks like Figure 12-5.
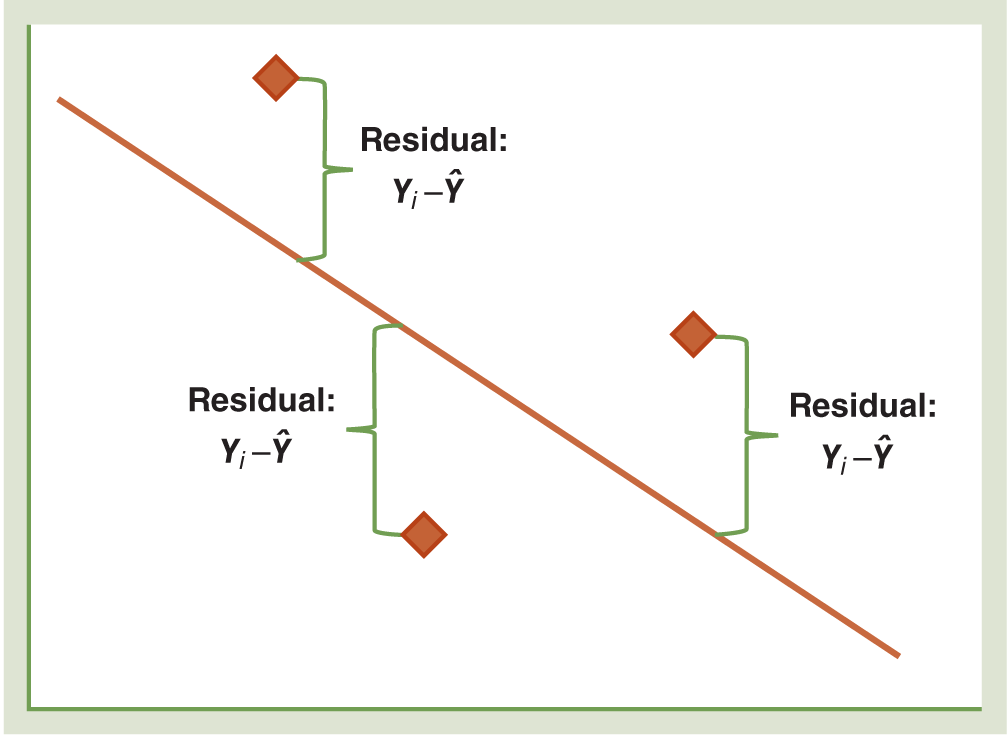
In this example, the fitted regression function equals 118.02 at an X of 7. Now, look at the data we observed to come up with this regression line. The observed value at an X of 7 was 125. Therefore, our residual value at an X of 7 is:
ε= 125 - 118.02 = 6.98
Let’s look at the data from our example and calculate the residuals for our model. Plug in each of the Xs to solve for Ŷ, and then subtract from the actual observed value to get the residual:
Observation | Blood Lead Level (mcg/dL) | IQ (Yi) | Ŷ | Residual |
|---|---|---|---|---|
1 | 7 | 125 | 118.02 | 6.98 |
2 | 18 | 109 | 112.65 | 3.65 |
3 | 22 | 110 | 110.69 | 0.69 |
4 | 25 | 117 | 109.23 | 7.77 |
5 | 29 | 110 | 107.27 | 2.73 |
6 | 37 | 98 | 103.36 | 5.36 |
7 | 44 | 94 | 99.94 | 5.94 |
8 | 56 | 90 | 94.08 | 4.08 |
9 | 64 | 84 | 90.17 | 6.17 |
10 | 100 | 81 | 72.58 | 8.32 |
Sum | 0 |
Notice that if you sum the residuals, you get a total of 0. This is always true for the normal error linear regression model.
Finally, it is important to point out the distinction between residuals and error. Remember the normal error regression model:
Yi = β0 + β1Xi + εi
It is really easy to confuse the final variable in this model, which represents the error, with residuals. Remember, residuals are a real construct. They are easily calculated from observed data. They represent the observed error. The error term in the model is more abstract. It represents all errors from the entire model, which has a much larger range than our observed data.
Last, there is always an error term in statistics, and in this equation, it is represented by the e. Just as there are no perfect people, there are no perfect estimates. The e just acknowledges that these statistical procedures are estimates taken from a sample, not the parameters you would find in a population model.
So if we wanted to put the previous equation into plain English using our example, we would say:
Fetal weight = a baseline value + an amount related to the length of the pregnancy + an amount related to the number of cigarettes smoked (probably negative) + a certain amount of error
Now hopefully that makes a little more sense.
Once you put in the data you have about the duration of the pregnancy and the number of cigarettes smoked, assuming this is a good regression equation, you should be able to predict an accurate fetal weight. For example, after we compute the regression equation, we determine the following:
Y = 0.25 + 0.79X1 - 0.15X2 + 0.5
A patient comes into your unit who is having some preterm labor at 7.5 months. She reports smoking 10 cigarettes a day. You might be concerned because you would predict the current fetal weight to be only 5.18 pounds.
Y = 0.25 + 0.79(7.5) - 0.15(10) + 0.5
Y = 5.175 pounds
Given that information, you might anticipate transferring the patient to a tertiary care facility if you are unable to stop the preterm labor.
Now the next question becomes: How do you know if you have a good regression equation? See, I knew you were going to ask that! Let’s look at some computer output to answer that question. There is another piece of good news when it comes to regression analysis, which is that you are not going to do any of the calculations yourself. We are going to make the computer do all the hard work, and then we are going to look at the results and see what we have figured out. However, for those of you who like to see the math to help understand the concept, check out the “From the Statistician” feature, where you can learn to calculate the regression coefficients manually.
From the Statistician
Brendan Heavey
Calculating Regression Coefficients (Parameter Estimates)
Regression coefficients (parameter estimates) can be calculated in many ways; the method you probably will choose is to use some computer software package to spit them out. However, I think it is an important exercise to see just what that computer package is doing behind the scenes.
Remember, the normal error simple linear regression model we have been looking at thus far is:
Yi = β0 + β1Xi + εi
This model represents how variables and parameters interact in a population. The true values for the parameters β1 and β2 are never really known. However, when we sample real data from a population, we can come up with very good estimates of what these parameters are, given a few reasonable assumptions, by using the following two equations. Notice that we need the result of the first equation to solve the second equation:
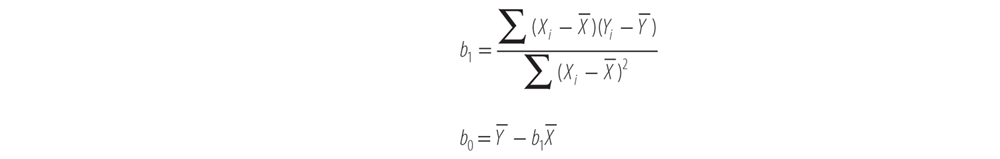
These equations are called the normal equations and are derived using a process called ordinary least squares.
To calculate these parameters, the first thing we do is find the denominator in the equation for b1:
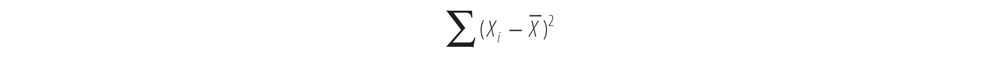
This denominator is an example of a very important concept in statistics called a sum of squares, which is calculated by subtracting the mean of a set of values from each of the observed values, squaring it, and then summing the results over the whole set. For instance, if we have a data set with two values:
X = {5,15}
Our mean value
, = 10 and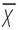
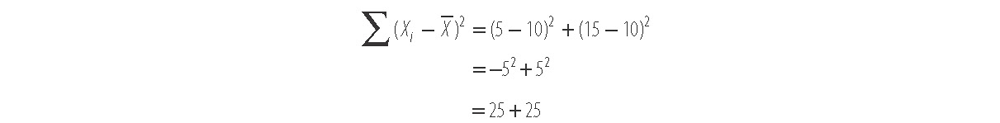
Notice that a value that is 5 below the mean and a value that is 5 above the mean both get the same amount of weight included in the overall sum (25 each). This sum allows us to quantify the overall distance away from the mean value that our data set contains, whether that distance is positive or negative.
The concept of a sum of squares is important for a number of reasons, not the least of which is that the equations we use to solve for our regression parameters are derived by calculating all possible sums of squared error in our regression model and selecting the one with the minimum error (also known in calculus as minimizing the sum of squared error). We will revisit the concept of a sum of squares when we learn about multiple regression analysis later in this chapter. Now there is a cliffhanger for you!
For now, let’s get back to solving for our estimates of the linear regression model by using data from our last “From the Statistician” feature, reproduced here:
You can see from our formulas that in order to solve for b1, we need to solve for
before we can solve for the sum of squares in the denominator. To do this, simply take the average of all our Xs: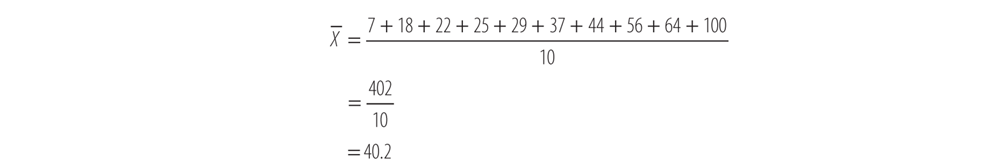
We now know that in our sample, the average BLL of the subjects is 40.2 mcg/dL. Now take each individual BLL (X) and subtract the mean BLL
we calculated for the whole sample and square the result (shown here in the third column):Now, sum the results of (Xi -
)2: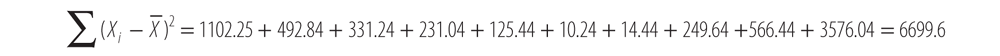
The denominator of our first parameter, b1, is 6699.6.
Now let’s go back and find the numerator of b1. First solve for the mean value of
. To do so, simply add all the observed IQ values (Y) and divide by the number of observations, 10:
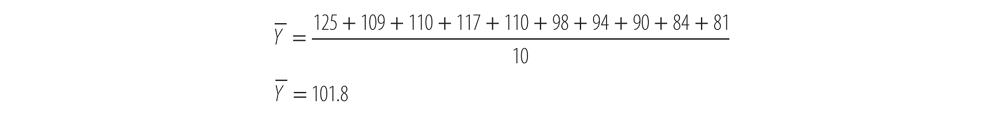
Now, subtract
from each of the Xs and from each of the Ys:Xi | Xi - X- | (Xi - X-)2 |
|---|---|---|
7 | -33.2 | 1102.24 |
18 | -22.2 | 492.84 |
22 | -18.2 | 331.24 |
25 | -15.2 | 231.04 |
29 | -11.2 | 125.44 |
37 | -3.2 | 10.24 |
44 | 3.8 | 14.44 |
56 | 15.8 | 249.64 |
64 | 23.8 | 566.44 |
100 | 59.8 | 3576.04 |
Now, multiply column 2 by column 4 in the previous table and sum the result to get the numerator:
Now, take this numerator, -3273.6, and divide by the denominator we solved for before, 6699.6:
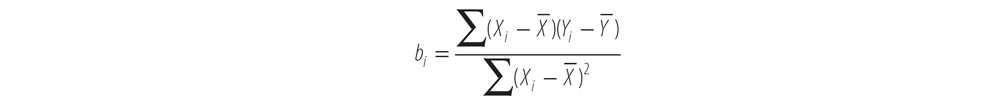
To come up with our first parameter estimate:
bi = -0.48863
Now, because we know b1,
, and, we can solve for b0 pretty easily:b0 =
- b0= 101.8 - (-0.48862*40.2)
= 101.8 + 19.6429
= 121.4429
And now we have our regression equation:
Yi = 121.4429 - 0.4886 Xi
Notice we left out the error term. Do you remember how to calculate the error of the sampled values? The residuals! The residuals represent the distance between our observed values and our calculated regression line. However, because our residuals sum to 0, we can leave that term out when looking at our overall model.
Let’s say I am interested in predicting an individual’s weight. My study includes information about age and height. When I put that information into the computer and complete a regression analysis, I have the following output:
Model Summary | ||||
|---|---|---|---|---|
Model | R | R-Squared | Adjusted R-Squared | Std. Error of the Estimate |
1 | 0.656a | 0.430 | 0.367 | 31.24864 |
2 | 0.922b | 0.850 | 0.813 | 16.99823 |
aPredictors: (Constant), age. bPredictors: (Constant), age, height. | ||||
Let’s look at each of these columns and figure out what the information means.
The first row (model 1) is when we only include the independent variable of age in the regression equation. The second row (model 2) is when we include age and then add the second independent variable of height to the model.
R is the multiple correlation coefficient that, when squared, gives you the R-squared (R2) value. Great, you say, and what does that mean? Well, R2 is important because it tells you the percentage of the variance in the dependent or outcome variable that is explained by the model you have built. In this example, the R2 of 0.850 on line 2 is when both age (independent variable 1) and height (independent variable 2) are included in the model. This just means including both age and height explains 85% of the variance seen in weight. See, not so bad. That R2 is handy!
You will also see the next column, or the adjusted R-squared, which is sometimes used to avoid overestimating R2 (the percentage of variance in the outcome explained by the model), particularly when you have a large number of independent variables with a relatively small sample size. In that case, reporting the adjusted R-squared would be a better idea. The takeaway idea here is this: if you plan to include a larger number of independent variables, you should plan for a larger sample size; otherwise, you are probably overestimating the percentage of variance explained by your regression model (R2)—and you know the statisticians will not like that!
From the Statistician
Brendan Heavey
A Closer Look at R-Squared
R-squared is a fantastic tool and is often the single statistic used to determine whether we can use a particular regression model. To derive R-squared requires looking at a regression equation from a slightly different view. The output from most statistical packages will show us a table with this view of our model, namely, the analysis of variance (ANOVA) table. It doesn’t matter which package you choose to use; you will get almost all the same information in this table. Here’s what the output looks like for the model in our previous example:
ANOVAa | |||||
|---|---|---|---|---|---|
Model | Sum of Squares | Degrees of Freedom (df) | Mean Square | F | Significance (Sig.) |
1 Regression | 1599.567 | 1 | 1599.567 | 39.985 | 0.000b |
Residual | 320.033 | 8 | 40.004 | ||
Total | 1919.600 | 9 | |||
aDependent variable: IQ. bPredictors: (Constant), BLL. | |||||
Coefficientsa | |||||
|---|---|---|---|---|---|
Model | Unstandardized Coefficients | Standardized Coefficients | |||
B | Std. Error | Beta | t | Sig. | |
1 (constant) BLL | 121.433 -0.489 | 3.695 0.077 | 0.913 | 32.870 -6.323 | 0.000 0.000 |
aDependent variable: IQ. | |||||
The three biggest concepts represented in the first table are:
- Sum of squares due to regression (SSR)
- Sum of squares due to error (labeled “Residual” here) (SSE)
- Total sum of squares
All three represent different reasons why Y values vary around their mean. Check out the diagram shown in Figure 12-6, which shows the total deviation partitioned into two components, SSR and SSE, for the first observed value.
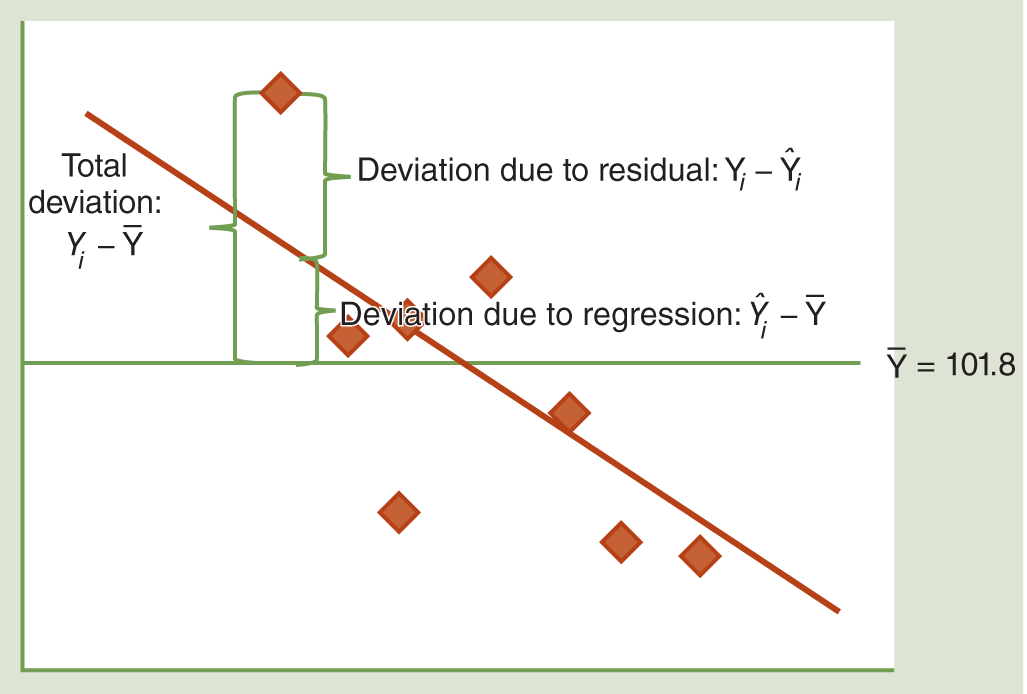
Here you can see how the total deviation of each observed Y value can be partitioned into two parts: the deviation due to the difference between the mean of Y and the regression line and the deviation between the observed value and the regression line. As it turns out, R-squared is simply the ratio of the second sum of squares over the total sum of squares.
Some variance is due to the regression itself, and some is due to error in the model. Here are the definitions of the sums of squares we’re interested in, the total sum of squares (SST0), the sum of squares due to regression (SSR), and the sum of squares due to error (SSE).
- SST0 represents the sum of the squared distance of each observed Y value from the overall mean of Y. You can see the distances that are squared and summed in Figure 12-6 under the heading “Total Deviation.”
- SSR represents the sum of the squared distance of the fitted regression line to the overall mean of Y. This is the variation that is due to the regression model itself.
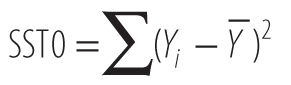
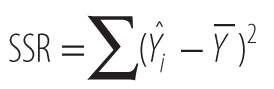
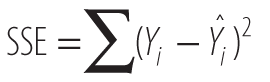
SSE represents the sum of the squared distance between the observed Y values and the regression line. This is the variation that is due to the difference between our observed values and our model, also known as the error in our model.
Let’s take a minute and calculate these values by hand for the model in our example.
To calculate SST0, subtract each observed Y from the mean of Y, and square that value like this:
Now, sum the right-most column, and we get our SST0:
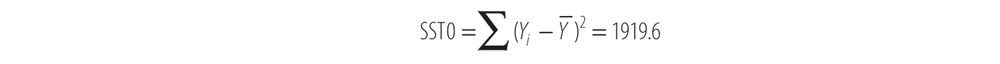
To calculate SSR, subtract the mean of Y from the fitted value on our regression line and square it:
Now, sum the right-most column, and we come up with the SSR:
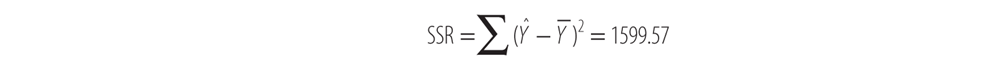
To calculate SSE, subtract the value of the regression line from each observed Y value and square it, like this:
SSE | |||
|---|---|---|---|
IQ [Yi] | Ŷ | (Yi - Ŷi) | (Yi - Ŷi)2 |
125 | 118.02 | 6.98 | 48.69 |
109 | 112.65 | -3.65 | 13.30 |
110 | 110.69 | -0.69 | 0.48 |
117 | 109.23 | 7.77 | 60.42 |
110 | 107.27 | 2.73 | 7.44 |
98 | 103.36 | -5.36 | 28.77 |
94 | 99.94 | -5.94 | 35.32 |
90 | 94.08 | -4.08 | 16.64 |
84 | 90.17 | -6.17 | 38.08 |
81 | 72.58 | 8.42 | 70.89 |
Now, sum the column on the far right to come up with the SSE:
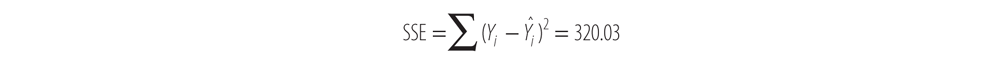
Now we have all the information we need in order to compute R2. To do so, compute:
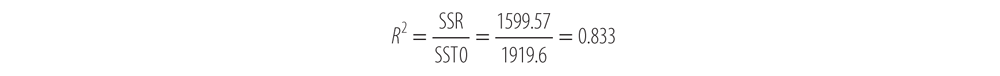
The section of a printout from SPSS that pertains to R-squared is shown here:
Model Summary | ||||
|---|---|---|---|---|
Model | R | R-Squared | Adjusted R-Squared | Std. Error of the Estimate |
1 | 0.913a | 0.833 | 0.812 | 6.32488 |
aPredictors: (Constant), BLL | ||||
So, our calculations match . . . hooray!
The standard error of the estimate tells you the average amount of error there will be in the predicted outcome (in this case, weight) using this model. (It is the standard deviation of the residuals for those statisticians among you. See the “From the Statistician” titled “What Is a Residual?” earlier in this chapter to learn more.) In this example, when using both age and height as independent variables, the weight you will predict will be off by an average of approximately 17 pounds. Obviously, you want your prediction to be as accurate as possible, so you would like to see the standard error of the estimate as close to zero as possible.
So now that you know what all of these columns mean, let’s go back to the R2 of 85%, which sounds pretty good. But you know that, as with all other statistical tests, we still need to look at the p-value to see if it is significant. With multiple regression, you need to see if the R2 is significant, but you also need to see if each of the independent variables is significant as well. You could have a significant R2 with an independent variable that really is not adding anything to the regression model, in which case you wouldn’t want to keep that variable in your equation.
Okay, so how do we do all of this? Well, let’s take it step by step. If I ask Statistical Package for the Social Sciences (SPSS) to tell me the R-squared change, I can see what happens to the R-squared each time I add another independent variable to the regression model.
This output shows me that when I added the variable of age, the R-squared went from 0 to 0.43, and it had a p-value of 0.028, which is significant, assuming an alpha of 0.05. When I added height to the model (which now includes age and height as independent variables), the R-squared went from 0.43 to 0.85 (from explaining 43% of the variance to explaining 85% of the variance), or a change of 0.42 (42%), which had a p-value of 0.001, which is also significant at an alpha of 0.05. Adding the second independent variable increased the accuracy of predictions made with this model by increasing the amount of variance accounted for by the model.
Model Summary | |||||||||
|---|---|---|---|---|---|---|---|---|---|
Change Statistics | |||||||||
Model | R | R- Squared | Adjusted R-Squared | Std. Error of the Estimate | R- Squared Change | F Change | df1 | df2 | Sig. F Change |
1 | 0.656a | 0.430 | 0.367 | 31.24864 | 0.430 | 6.788 | 1 | 9 | 0.028 |
2 | 0.922b | 0.850 | 0.813 | 16.99823 | 0.420 | 22.416 | 1 | 8 | 0.001 |
aPredictors: (Constant), age. bPredictors: (Constant), age, height. | |||||||||
If we look at the next table SPSS gives us, you will see an ANOVA table.
In this table you can see the p-value for both the first model (just age included) and the second (age and height included). The first model had a p-value of 0.028, and the second model had a significance level of 0.001.
The last table we see in SPSS shows us the coefficients, or the b values, in our regression equation.
ANOVAa | |||||
|---|---|---|---|---|---|
Model | Sum of Squares | df | Mean Square | F | Sig. |
1 Regression | 6628.609 | 1 | 6628.609 | 6.788 | 0.028b |
Residual | 8788.300 | 9 | 976.478 | ||
Total | 15416.909 | 10 | |||
2 Regression | 13105.391 | 2 | 6552.695 | 22.678 | 0.001c |
Residual | 2311.518 | 8 | 288.940 | ||
Total | 15416.909 | 10 | |||
aDependent variable: Weight. bPredictors: (Constant), age. cPredictors: (Constant), age, height. | |||||
Coefficientsa | |||||||
|---|---|---|---|---|---|---|---|
Unstandardized Coefficients | Standardized Coefficients | 95.0% Confidence Interval for B | |||||
Model | B | Std. Error | Beta | t | Sig. | Lower Bound | Upper Bound |
1 (Constant) | 93.552 | 31.582 | 2.962 | 0.016 | 22.108 | 164.996 | |
age | 2.348 | 0.901 | 0.656 | 2.605 | 0.028 | 0.309 | 4.386 |
2 (Constant) | -584.801 | 144.305 | -4.053 | 0.004 | -917.568 | -252.034 | |
age | 1.712 | 0.508 | 0.478 | 3.368 | 0.010 | 0.540 | 2.884 |
height | 10.372 | 2.191 | 0.672 | 4.735 | 0.001 | 5.320 | 15.423 |
aDependent variable: Weight. | |||||||
When we use regression to make predictions, we should look at the column for the unstandardized coefficients (B). First, the B of 584.8 is the constant for our prediction equation. Then you will see the beta coefficients for our independent variables of age and height. This is just the b value in the regression equation. It tells us what a one-unit change in the independent variable will do to the outcome or dependent variable when the other independent variables are held constant. In this example, including both variables in the model gives us b1 = 1.712 and b2 = 10.372. Yikes, we are getting really statistical here—how about a little plain English?
This means that when we control for height, every additional year of age adds 1.71 pounds, and when we control for age, every additional inch of height adds 10.37 pounds. That should make sense—being taller and getting older both tend to add weight—not a pretty picture but the reality most of us face anyhow. Both age (p = 0.010) and height (p = 0.001) are significant, which means even when you control for the other, both add to the ability of the model to predict weight. If one of these variables was not significant at this point, it would indicate that when we controlled for the other variables, this variable was not significantly adding to the model or did not increase the ability of the model to make an accurate prediction.
Where Students Often Make Mistakes
When evaluating regression models, most students understand that the significance of R2 tells you if your regression model is significant. However, a significant predictor model does not mean that every independent variable that is included is adding to the model significantly. When another independent variable is added to a model, the R2 will increase even if the added independent variable is not significant. To see if an additional independent variable is significant, students must look at the significance of the R2 change when that variable is added to the model. If the R2 change is significant, that independent variable should stay in the model. If it isn’t, it is just increasing the size of the error associated with the prediction and should be removed.