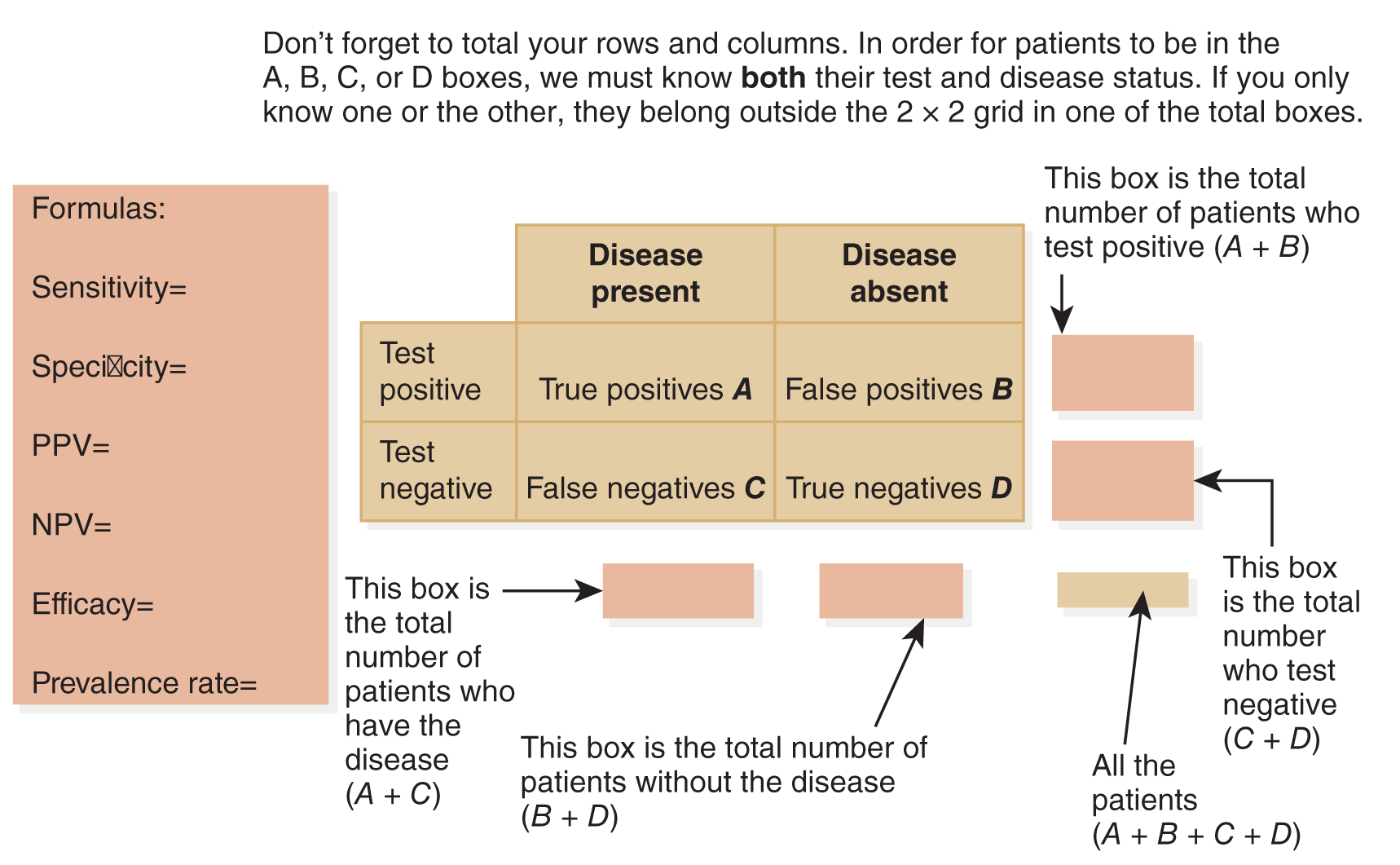
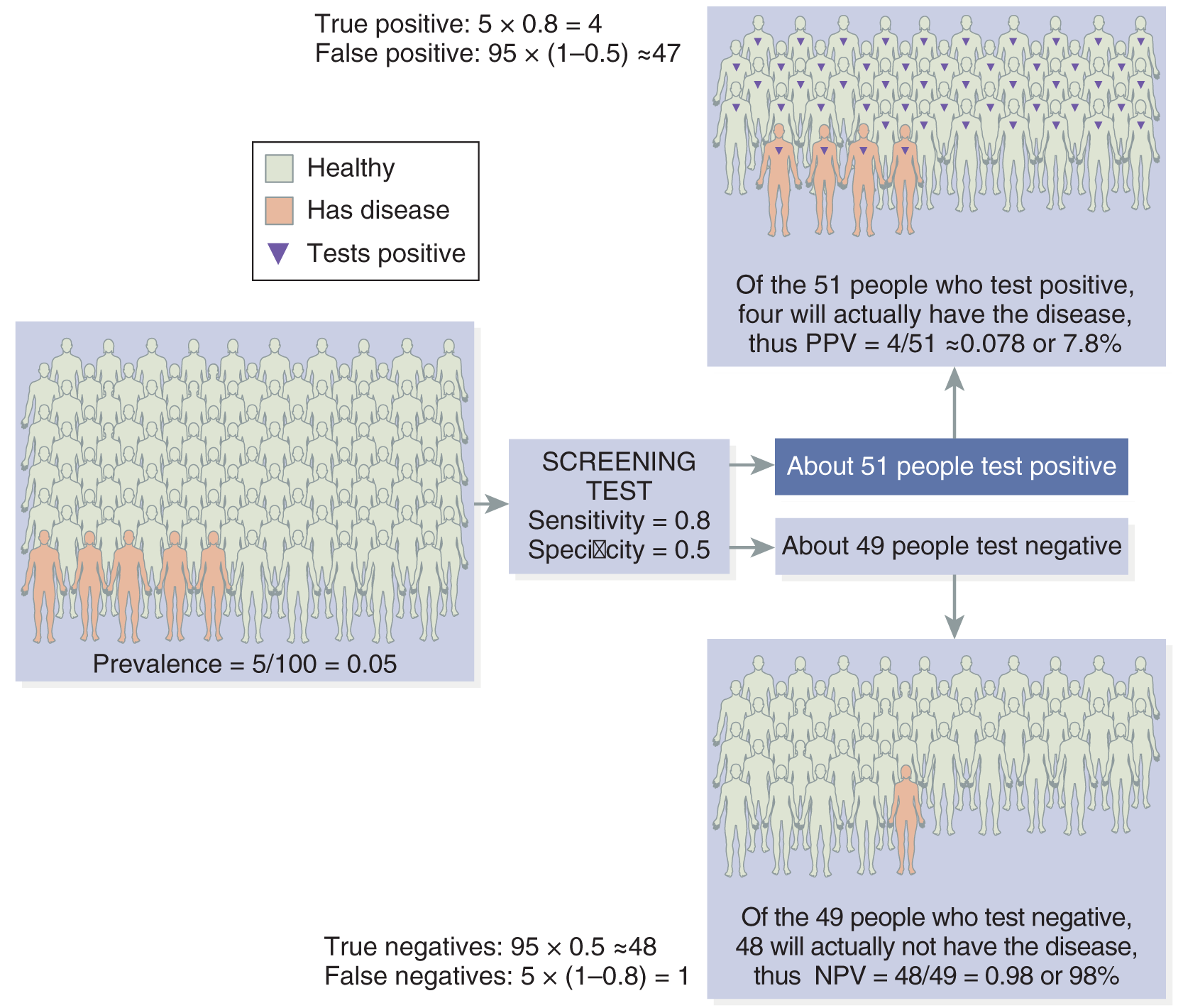
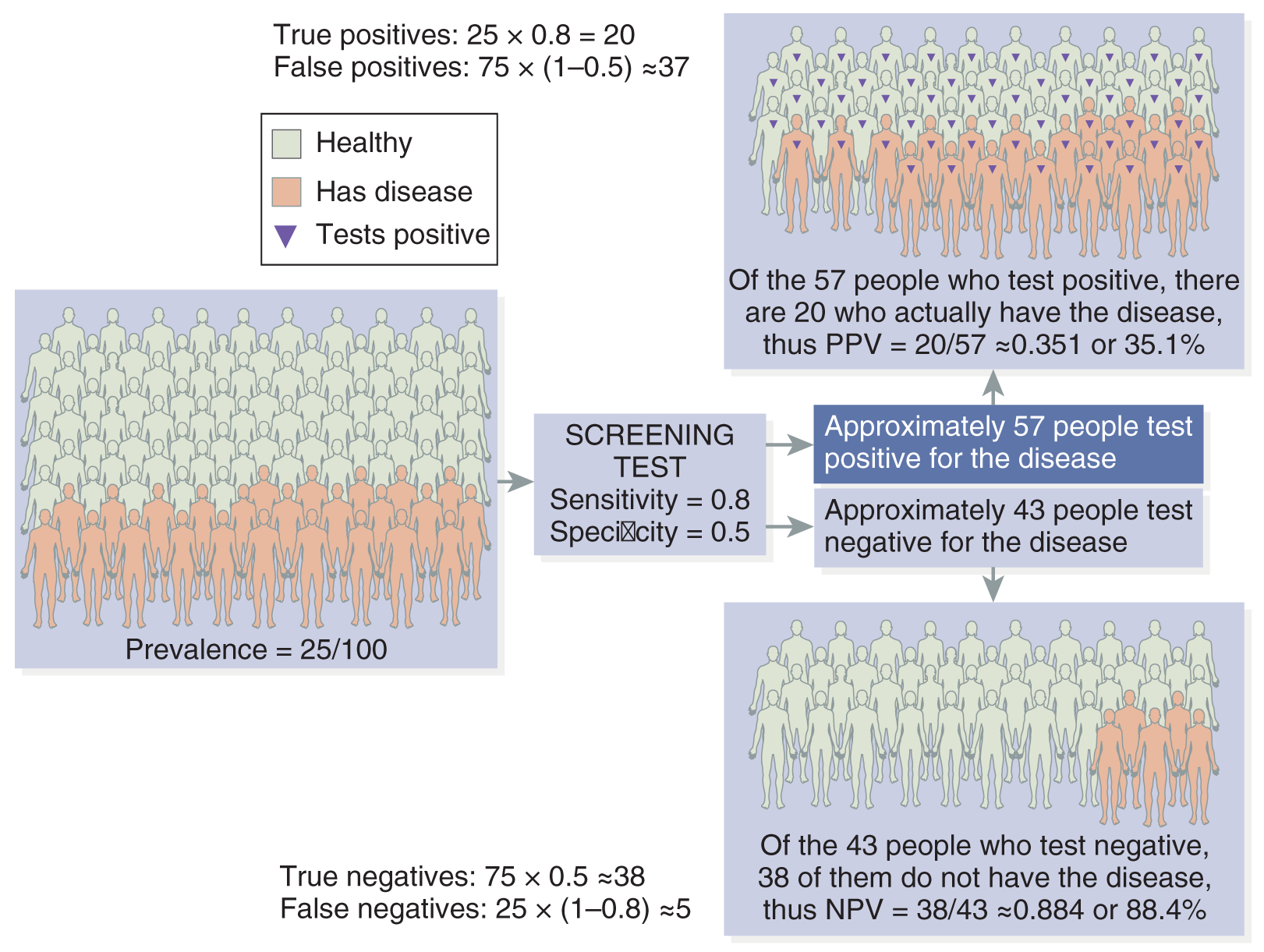
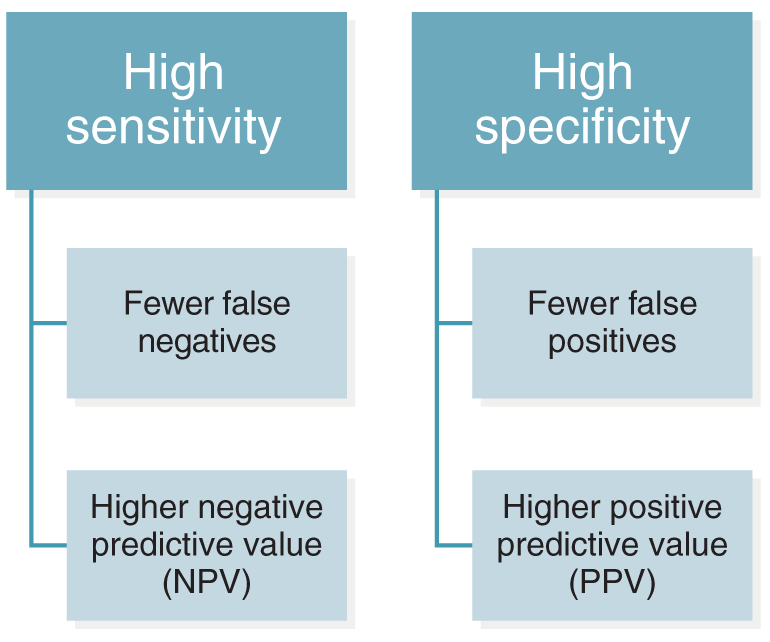
Reliability means that your measurement tool is consistent or repeatable. When you measure your variable of interest, do you get the same results every time? Reliability is different from accuracy or validity. Suppose, for example, that you measure the weight of the study participants, but your scale is not calibrated correctly: it is off by 20 pounds. When your 170-pound participant gets on the scale, it shows she is 190 pounds. She steps off and back on three times, and each time it indicates 190 pounds. You get the same measurement every time she steps on the scale; thus, the measurement is repeatable and reliable. However, in this case, it is not accurate or valid, not to mention that all of your subjects will drop out of your study because they dread getting on your scale! The bottom line is that a measure can be reliable and not valid, but it can’t be valid and not reliable. Think of it this way: for an instrument to be accurate (valid), it must be accurate and reliable.
Three main factors relate to reliability: stability, homogeneity, and equivalence. Stability is the consistent or enduring quality of the measure. A stable measure:
- Should not change over time.
- Should have a high correlation coefficient when administered repeatedly. The correlation coefficient measures how closely one measurement is related to a second measurement. For example, if you measure the temperature of a healthy individual six times in an hour, the readings should be approximately the same and have a high correlation coefficient. (Of course, that patient may be really sick of having you around, but I am sure your excitement at discovering that you have a stable measure will make it all worthwhile!)
You need to evaluate the stability of your measurement instrument at the beginning of the study and throughout it. For example, if your thermometer breaks, the instrument that was once stable is no longer available. As a result, your ongoing results are no longer reliable, and you need to have a protocol to figure out quickly how to reestablish stability.
The second quality of a reliable measure, homogeneity, is the extent to which items on a multi-item instrument are consistent with one another. For example, your survey may ask several questions designed to measure the level of family support. The questions may be repeated but worded differently to see whether the individuals completing the survey respond in the same way. For example, one question may ask, “What level of family support do you feel on most days?” and the choices may be high, medium, and low. Later in the survey, you may ask the individual to indicate on a scale of 1 to 10 the degree of family support felt on an average day. If the instrument has homogeneity, those who answered that they had a medium level of family support on most days should also be somewhere around the middle of the 1-10 scale. If so, then your instrument is said to have internal consistency reliability.
Internal consistency reliability is useful for instruments that measure a single concept, such as family support, and is frequently assessed using Cronbach’s alpha. Cronbach’s alpha ranges from 0 (no reliability in the instrument scale) to 1 (perfect reliability in the instrument scale), so a higher value indicates better internal consistency reliability. You may hear more about this test in future statistics or research classes, but right now, you just need to know that it can be used to establish homogeneity or internal consistency reliability (Nieswiadomy, 2008).
The third factor relating to reliability is equivalence. Equivalence is how well multiple forms of an instrument or multiple users of an instrument produce/obtain the same results. Measurement variation reflects more than the reliability of the tool itself; it may also reflect the variability of different forms of the tool or variability due to various researchers administering the same tool. For example, if you want to observe the color of scrubs worn by 60 nurses at lunchtime on a particular day, you might need help in gathering that much data in such a short period of time. You might ask two research assistants to observe the nurses. When you have more than one individual collecting data, you should determine the inter-rater reliability. One way to do this is to have all three individuals collecting data observe the first five nurses together and then classify the data individually. For example:
- You report that the first five nurses are wearing blue, green, green, orange, and pink scrubs.
- The second research assistant reports that the first five nurses are wearing teal, lime, lime, tangerine, and rose scrubs.
- The third reports that the first five nurses are wearing blue, green, green, orange, and pink scrubs.
In this example, the inter-rater reliability between you and the third data collector is 100%, whereas it is 0% between you and the second collector. You have clearly identified a problem with the instrument’s inter-rater reliability.
One way to increase reliability is to create color categories for data collection, such as blue, green, orange, yellow, and other. In this case:
- You report that the first five nurses are wearing blue, green, green, orange, and other.
- The second data collector reports that the nurses are wearing blue, green, green, other, and other.
- The third data collector matches your selections again.
Clearly, you have improved the inter-rater reliability, but some variability is left because of the collectors’ differences in interpretation of colors. With this information, you may decide that the help of the second data collector isn’t worth the loss in inter-rater reliability. You might run the study with only two data collectors, or you may decide to sit down, define specific colors with the second data collector, and then reexamine the inter-rater reliability. You must consider this concern whenever the study requires more than one data collector in all such cases.
The readability of an instrument can also affect both the validity and reliability of the tool. If your study participants cannot understand the words in your survey tool, there is a very good chance they will not complete it accurately or consistently, which would ruin all your hard work. Good researchers assess the readability of their instrument before or during the pilot stages of a study.
One last point to remember is that the validity and reliability of an instrument are not inherent attributes of the instrument but are characteristics of the use of the tool with a particular group of respondents at a specific time. For example, a tool that has been shown to be valid and reliable when used with an urban elderly population may not be valid and reliable when used with a rural adolescent population. For this reason, the validity and reliability of an instrument should be reassessed whenever that instrument is used in a new situation.