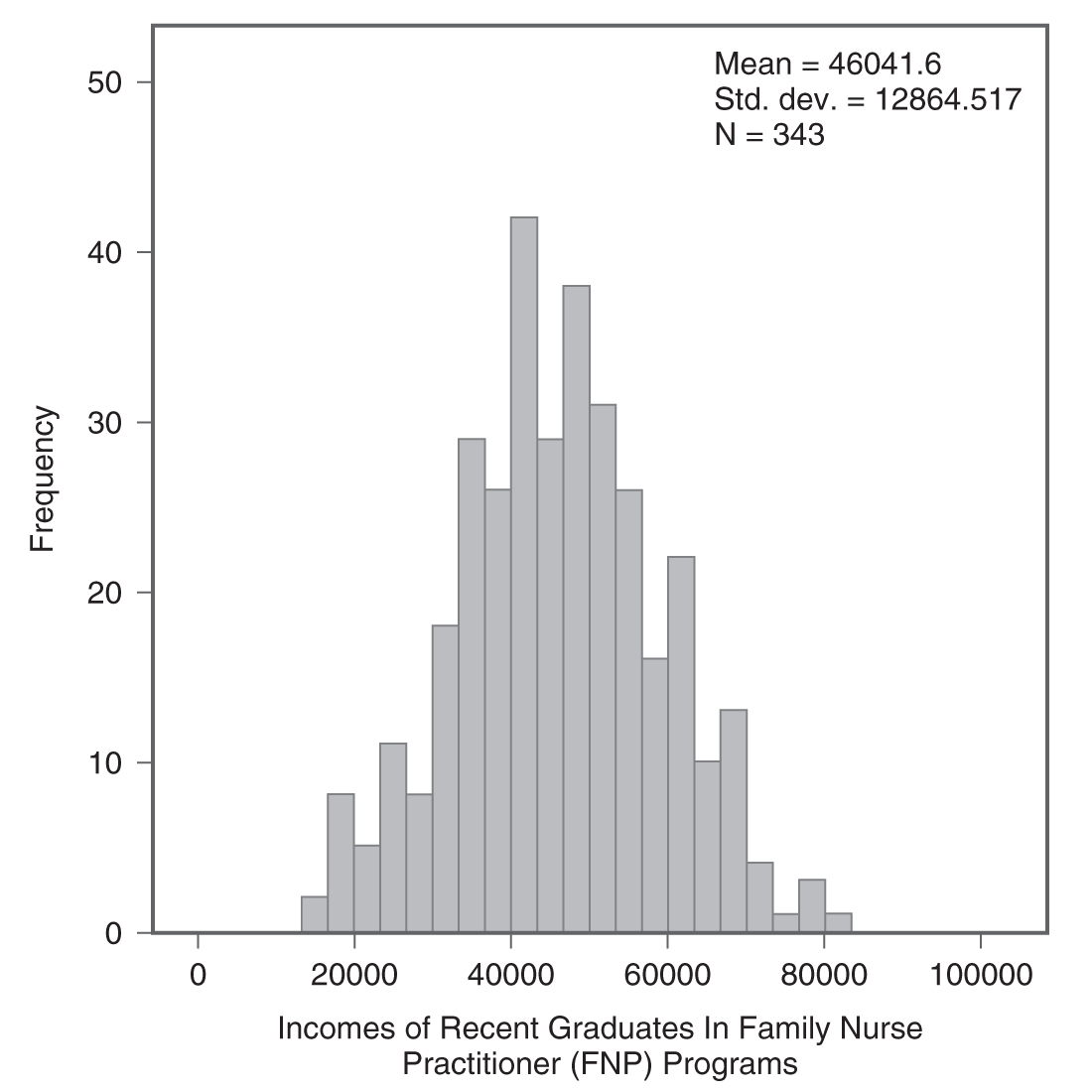
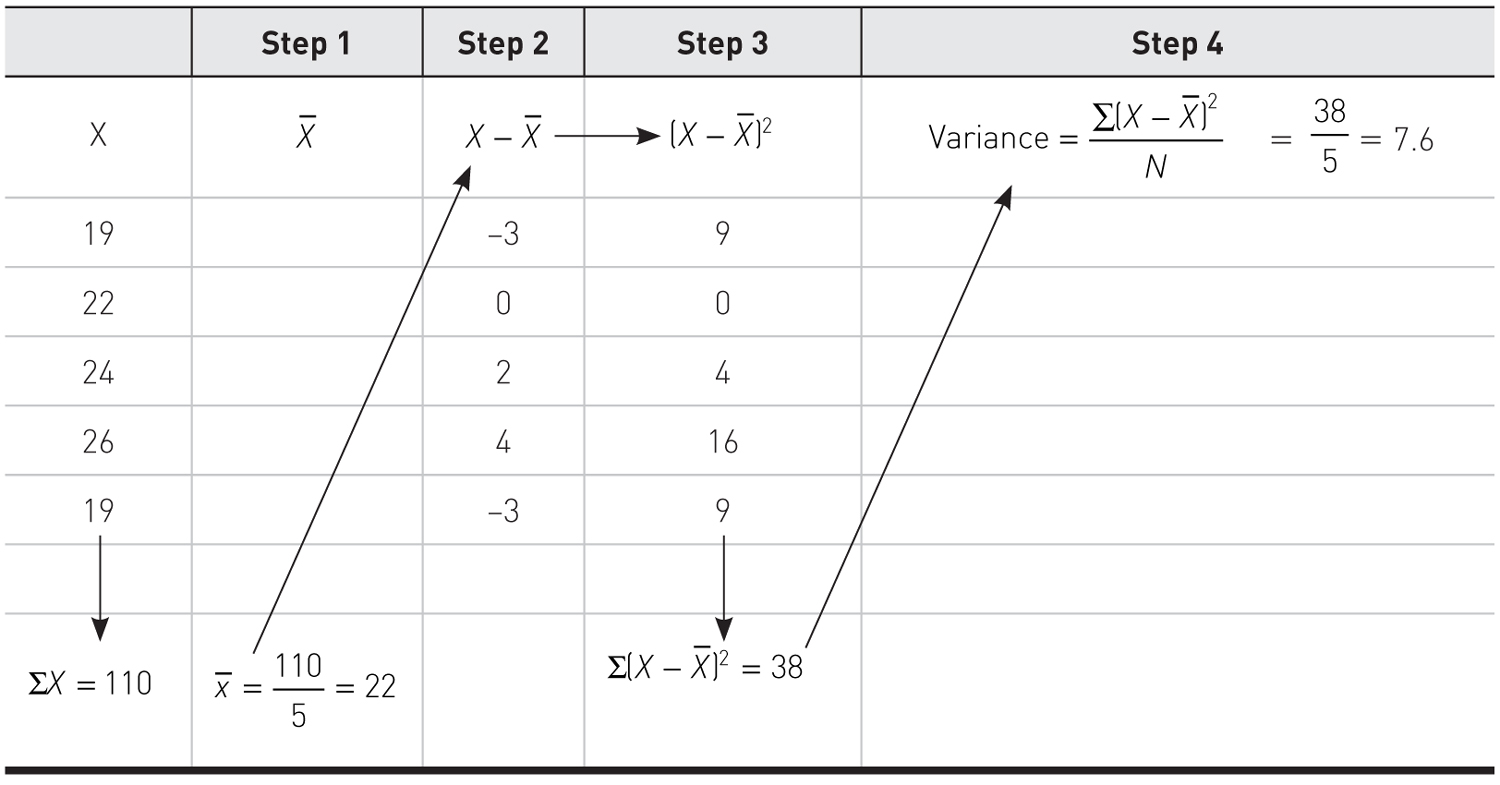
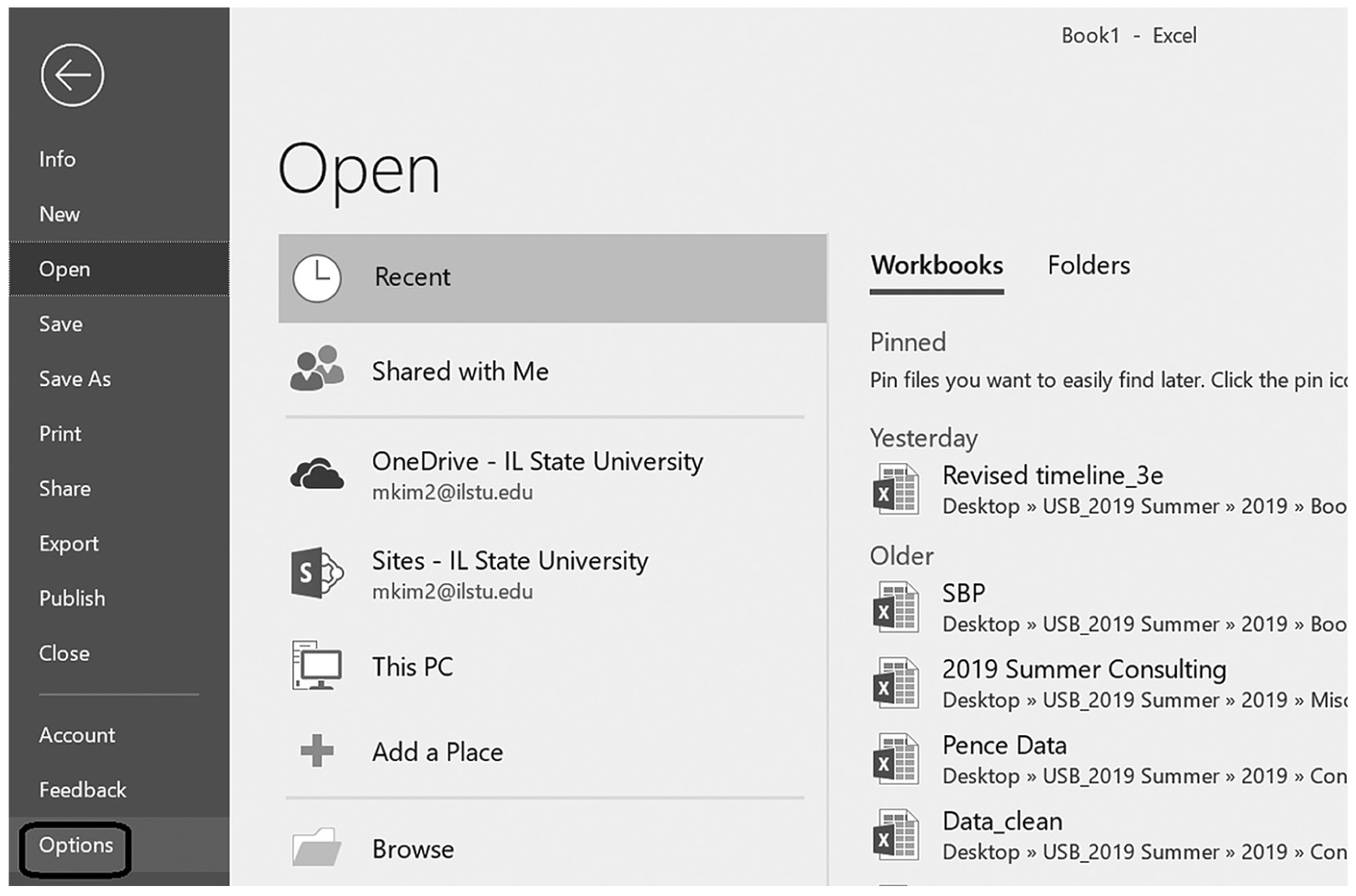
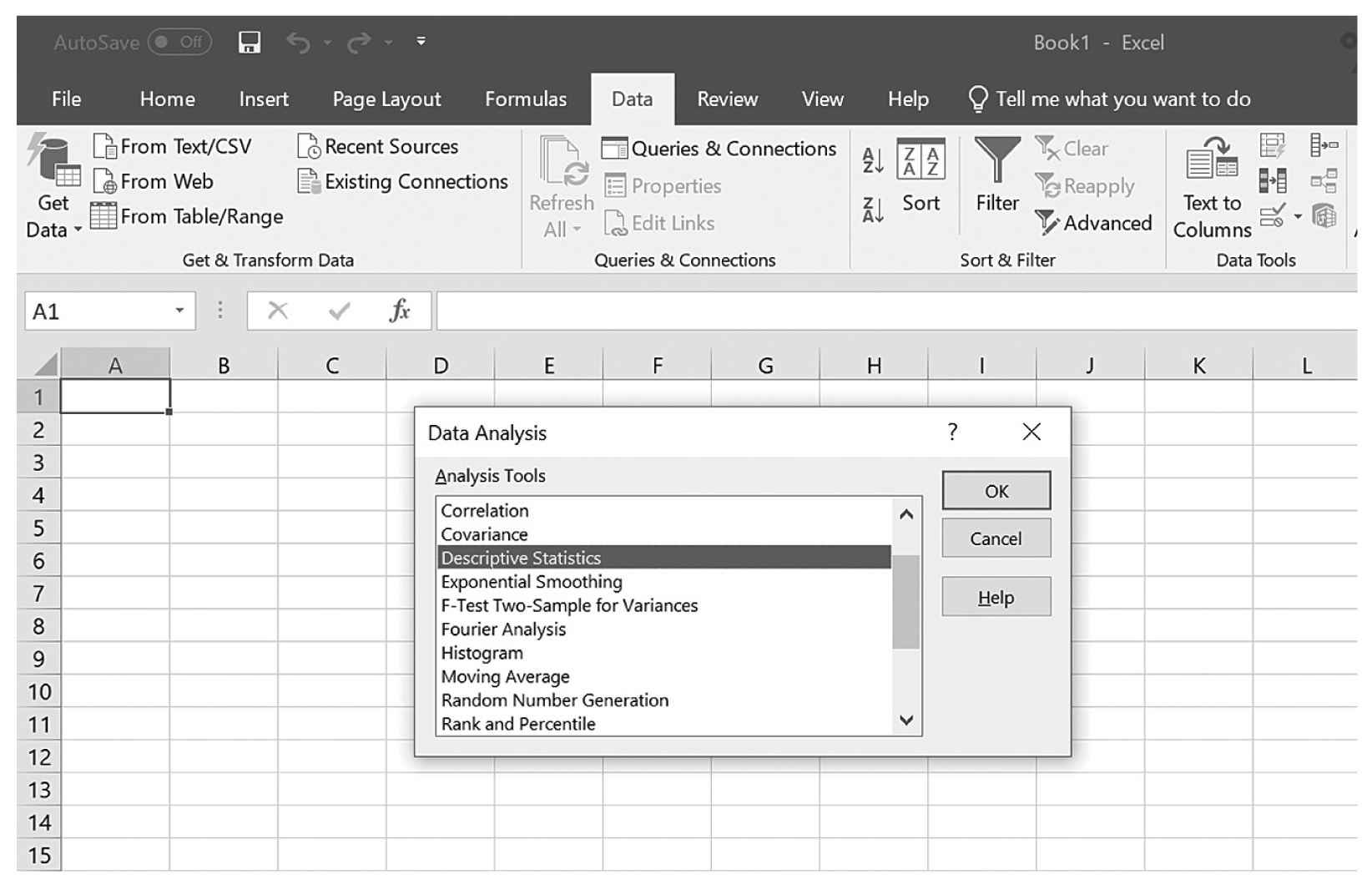
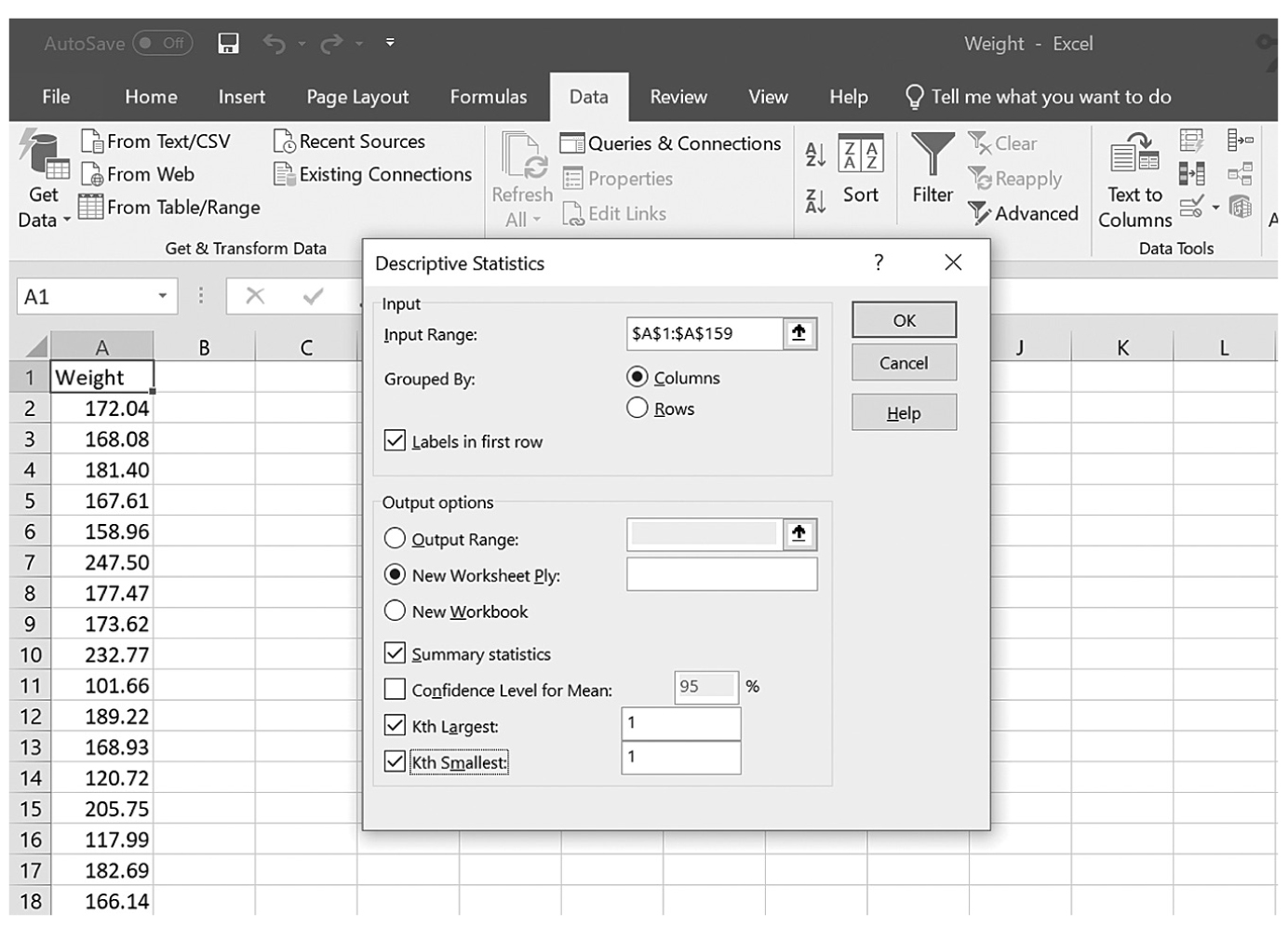
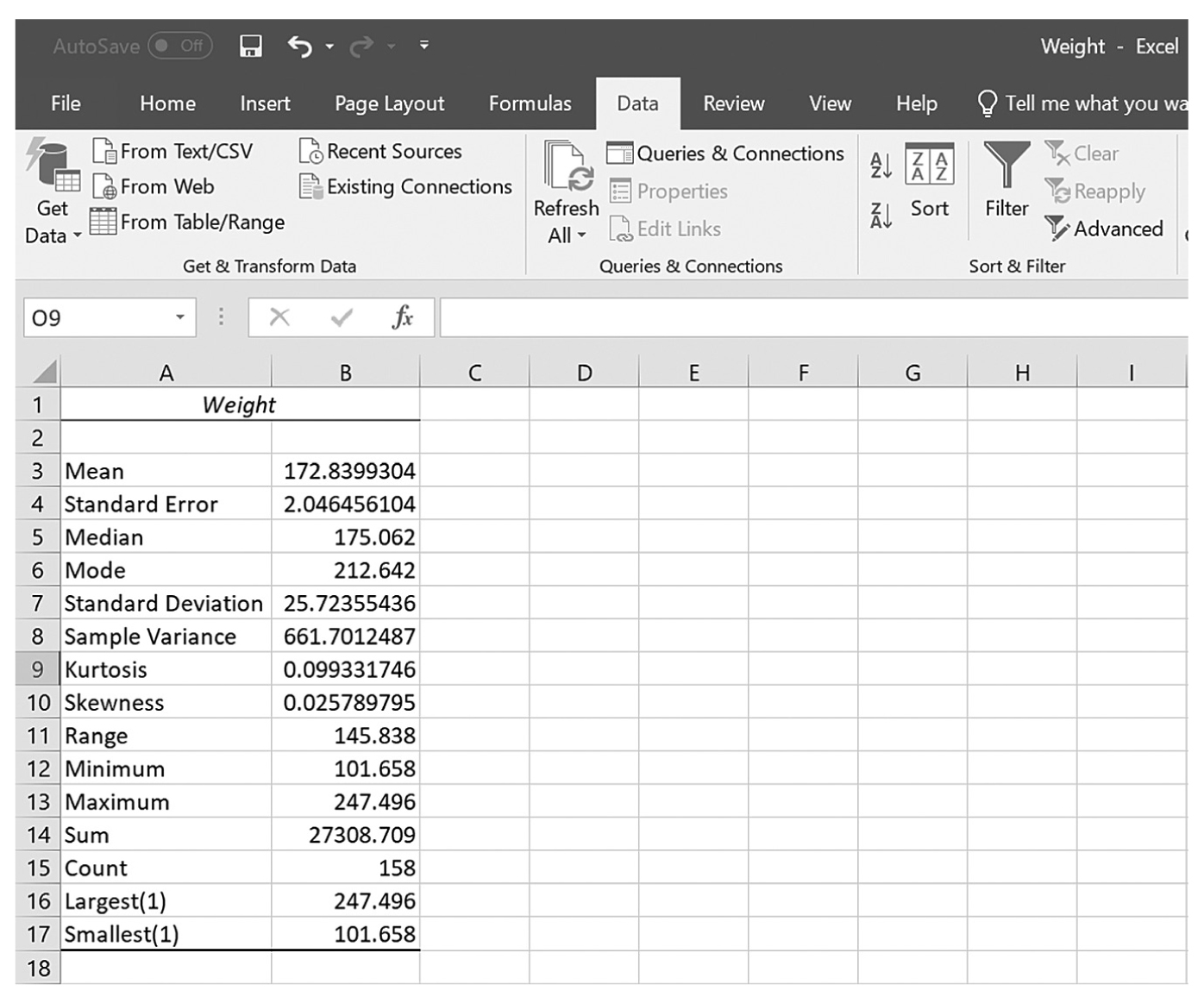
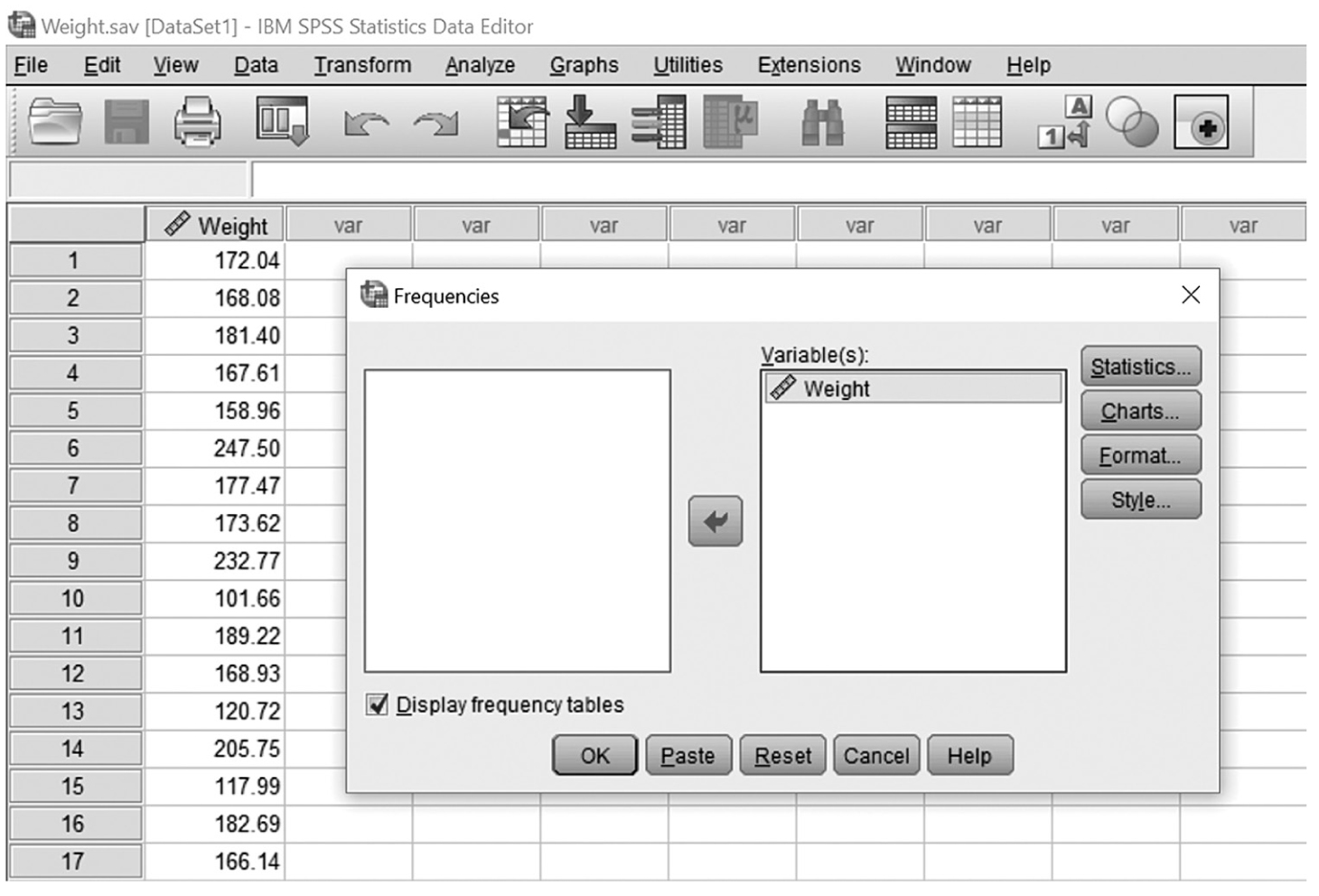
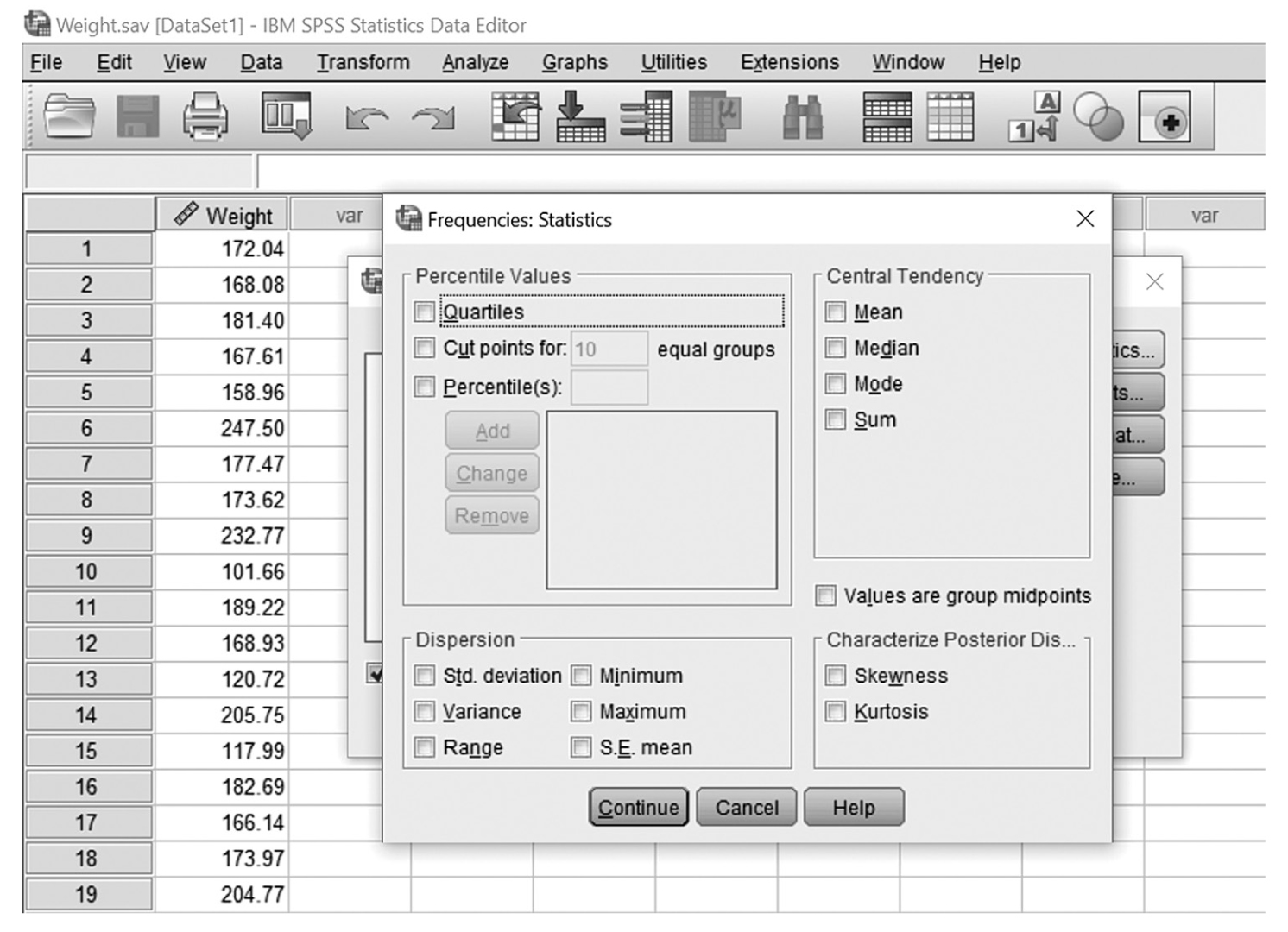
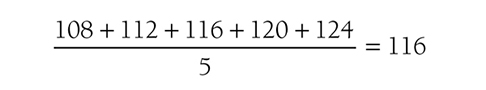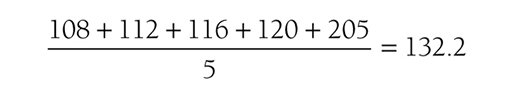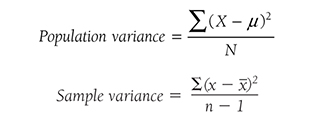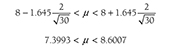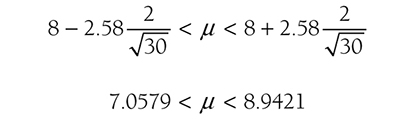Descriptive statistics help us understand whether the distribution of a continuously measured variable is normal. Figure 6-12 is an example of normal distribution of a variable, age. Some notable characteristics of normal distribution are summarized in the text that follows.
Histogram with overlying normal curve.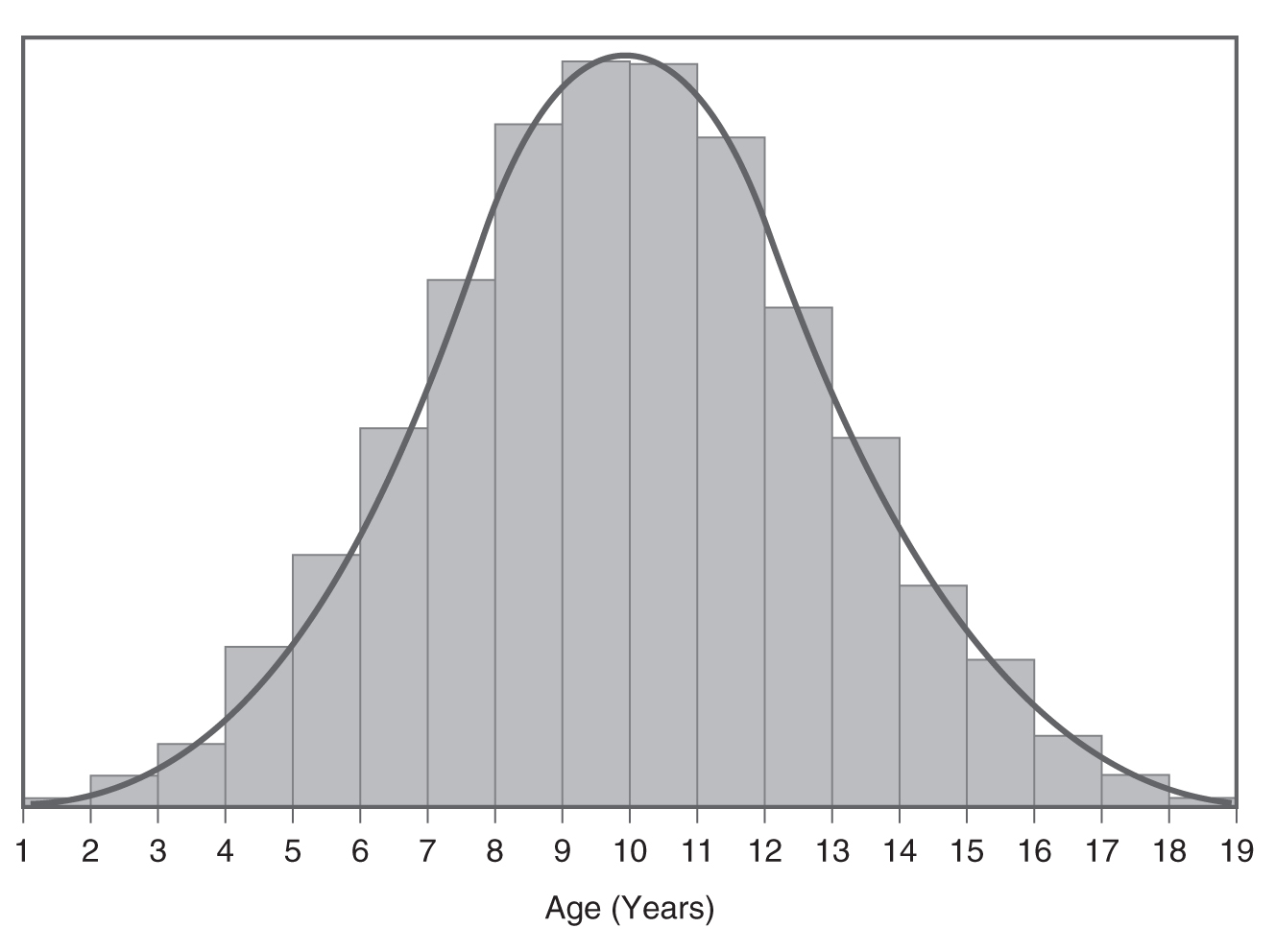
A histogram showing the age and the normal distribution are shown.
When a distribution is normal, the distribution is symmetrical and the area on both sides of the distribution from the mean is equal; in other words, 50% of the data values in the set are smaller than the mean and the other 50% are larger than the mean. In a normal distribution, the mean is located at the highest peak of the distribution, and the spread of a normal distribution can be presented in terms of the standard deviation.
Why do we care about this normal distribution so much? The most important reason is that many human characteristics fall into an approximately normal distribution, and the measurement scores are assumed to be normally distributed when conducting most statistical analyses. Therefore, if the variable is not normally distributed, the statistical results may not be trustworthy. We will discuss this more in Chapter 8.
Note that no data are ever exactly/perfectly normally distributed in reality. If that is so, how do we know whether a collected data set is normally distributed? We can begin with a visual display of the data in a histogram to see if the data set is normally distributed. However, a visual check alone may not be sufficient to know whether the data are normally distributed. There are statistical measures, skewness and kurtosis, which, along with a histogram, allow us to determine whether the data set is normally distributed. Skewness is a measure of whether the set is symmetrical or off-center, which means that the probabilities on both sides of the distribution are not the same. Kurtosis is a measure of how peaked a distribution is. A distribution is said to be normal when both measures of skewness and kurtosis fall within the -1 to +1 range, and nonnormal if both measures fall either below -1 or above +1. Note that these measures can be selected in the same window as measures of central tendency and variability, which we just discussed.
Characteristics of Normal DistributionIt is bell-shaped and symmetrical.
- The area under a normal curve is equal to 1.00 or 100%.
- 68% of observations fall within one standard deviation from the mean in both directions.
- 95% of observations fall within two standard deviations from the mean in both directions.
- 99.7% of observations fall within three standard deviations from the mean in both directions.
- Many normal distributions exist with different means and standard deviations.
|
Figure 6-13 shows what percentage of the data set falls within how many standard deviations away from the mean. If a variable follows a normal distribution, these rules can be applied to understand the distribution of the variable in terms of the mean and the standard deviation. In addition, different normal distributions can be found when the mean and the standard deviation are defined as shown in Figures 6-14 and 6-15.
Area under a normal distribution.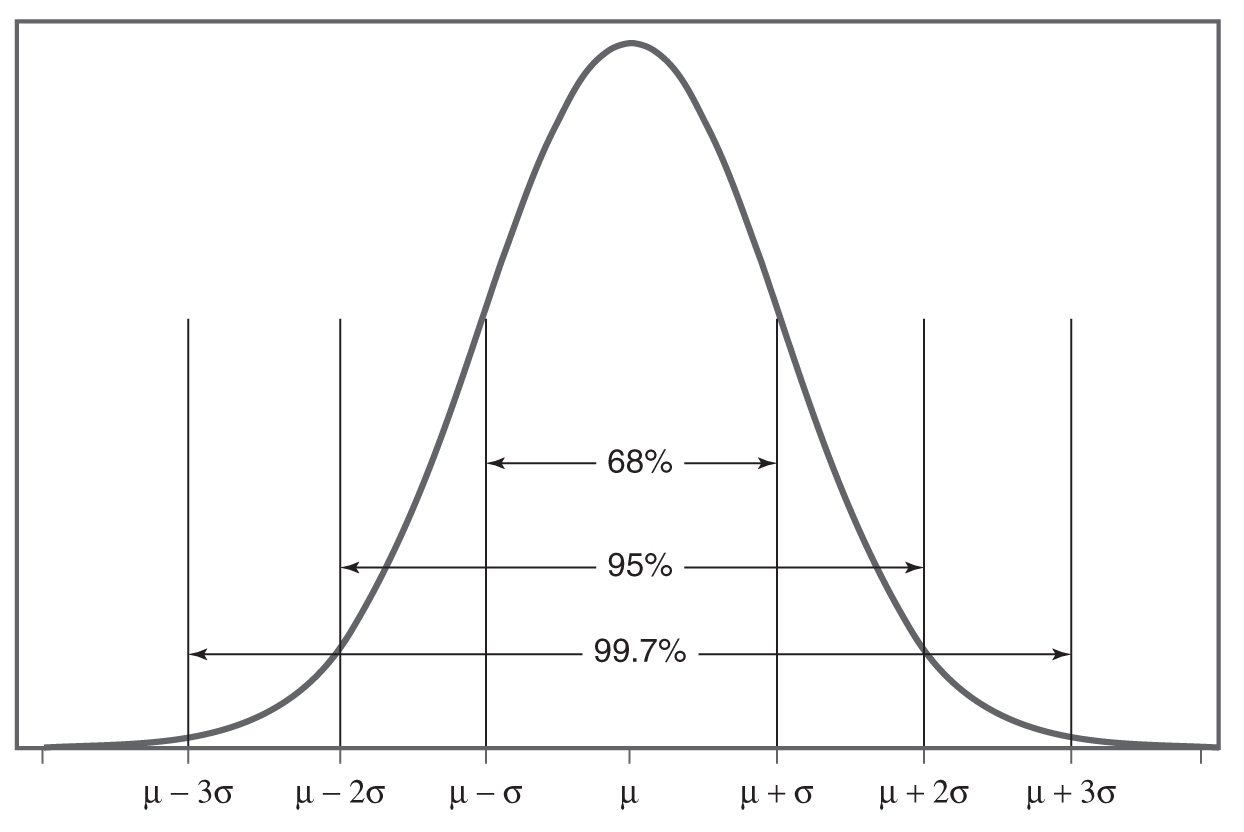
A curve shows the area under a standard normal distribution.
Normal distributions with different means.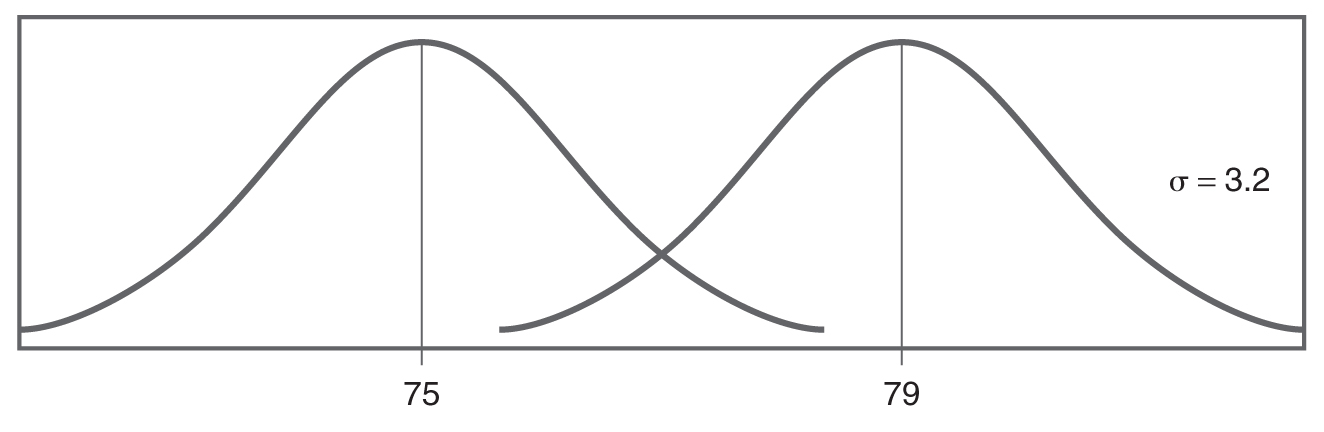
Two normal distribution curves show the mean, 75 and 79, respectively. The standard deviation equals 3.2.
Normal distributions with different standard deviations.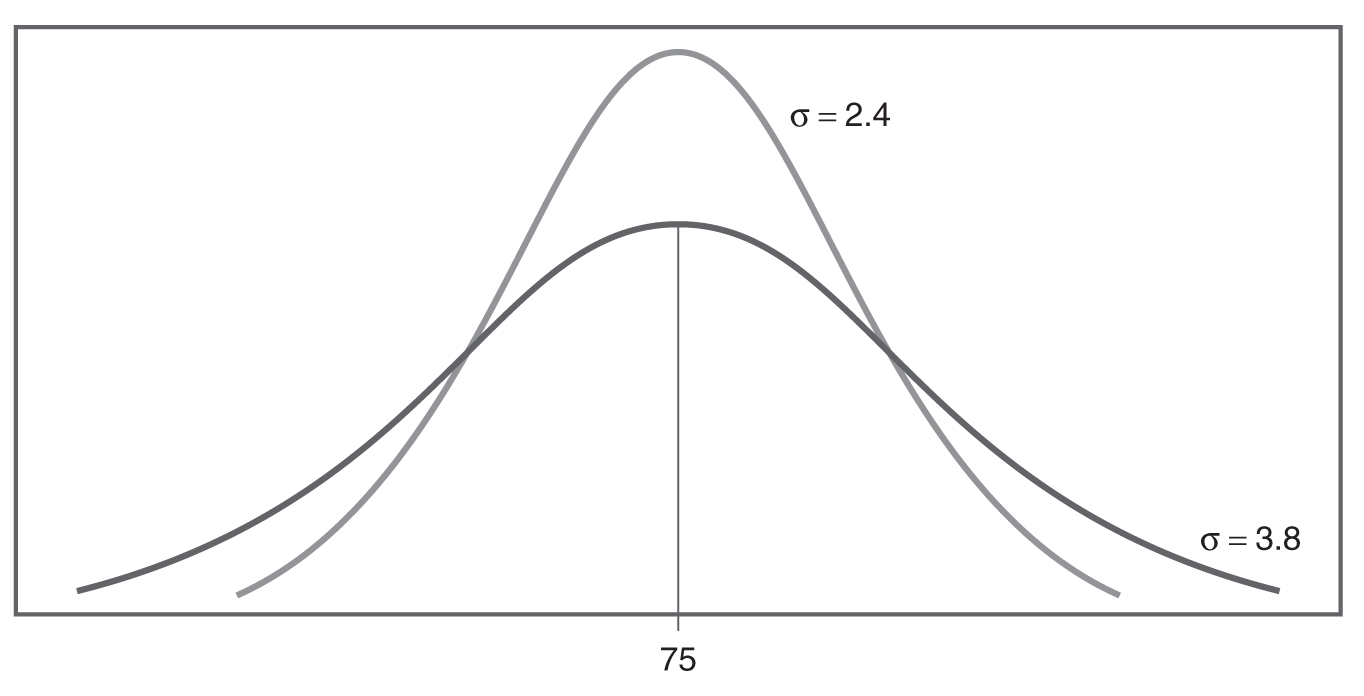
Two normal distribution curves with mean 75, show different standard deviations, 2.4 and 3.8, respectively.
We can apply the principles of the normal distribution by computing a standardized score such as a z-score. These standardized scores are useful for comparing scores computed on different scales. For example, let us consider a student who is wondering about the final exam scores in statistics and research courses. The student scored 79 out of 100 on the final exam in the statistics course and 42 out of 60 in the research course. Can the student conclude that their performance was better in statistics? Before drawing such a conclusion, the student will need to examine the distribution of scores on the two final exams. Let us assume that the final exam in statistics had a mean of 75 with a standard deviation of 3, and the final exam in research had a mean of 40 with a standard deviation of 2.5. It seems that the student did better than the average in both classes, but it is still difficult to judge in what course the student performed better. This question cannot be directly answered using different normal distributions because they have different means and standard deviations (i.e., they are not on an identical scale, which is necessary to make direct comparisons).
We need somehow to put these two different distributions on the same scale so that we can make a legitimate comparison of the student’s performance; a standard normal distribution is the solution. By definition, a standard normal distribution is one in which all scores have been put on the same scale (standardized). These standardized scores (also known as z-scores) represent how far below or above the mean a given score falls and allows us to determine percentile/probabilities associated with a given score.
Figure 6-16 shows a graphical transition from a general normal distribution to a standard normal distribution. Characteristics of the standard normal distribution are summarized in the box on the page that follows.
Transition from a general normal distribution to a standard normal distribution.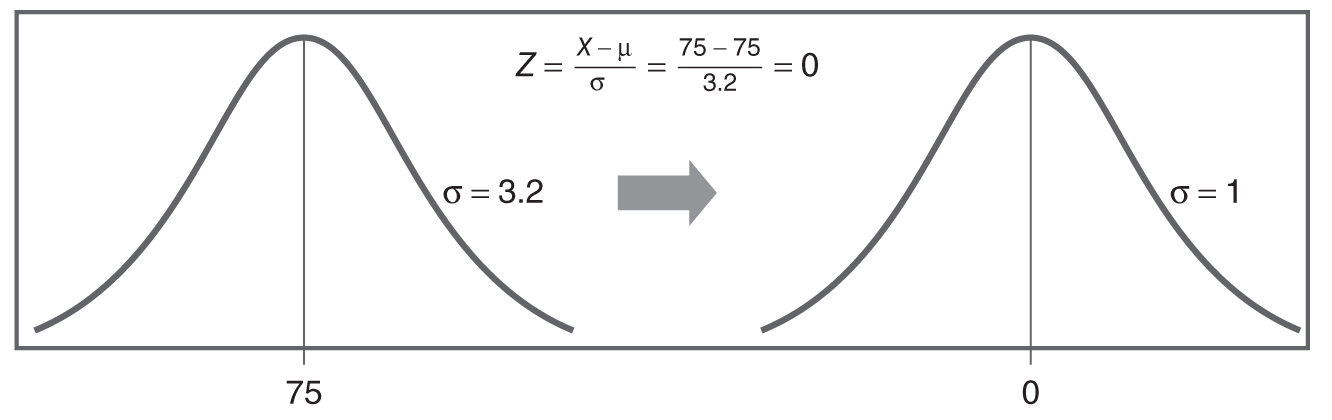
A normal distribution curve with mean 75 and standard deviation 3.2 is transitioned to a standard normal distribution curve with mean 0 and standard deviation 1. A formula reads, Z equals X minus mu, over, sigma equals 75 minus 75, over 3.2 equals 0.
To compute a z-score, you will need two pieces of information about a distribution: the mean and the standard deviation. Z-scores (standardized scores) are computed using the following equation, where the population mean (μ) is subtracted from the raw score and divided by the population standard deviation (σ). Z-scores are calculated so that positive values indicate how far a score is above the mean, and negative values indicate how far a score falls below the mean. Whether positive or negative, larger z-scores mean that scores are far away from the mean, and smaller z-scores mean that scores are close to the mean:
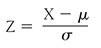
Z-scores will be positive when a student performs better than the mean on a test—the numerator of the previous equation will be positive. In contrast, z-scores will be negative when a student performs below the mean. Let us consider an example test, again a statistics final exam, with a mean of 78 and standard deviation of 3. Suppose that Brian has a final exam score of 84. His z-score will be:
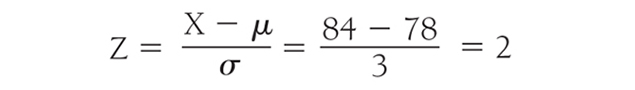
Characteristics of the Standard Normal DistributionThe standard normal distribution has a mean of 0 and a standard deviation of 1.
- The area under the standard normal curve is equal to 1.00 or 100%.
- Z-scores have associated probabilities, which are fixed and known.
|
What does Brian’s z-score of 2 mean in terms of his performance relative to the average person who took this statistics final exam? First, we can see that Brian did perform better than the average person on this final exam. Second, his z-score of 2 tells us that his score is two standard deviations above the mean of 0 (i.e, average score of 78), because a standard normal distribution has a standard deviation of 1. However, this second point about Brian’s score does not really make perfect sense to us yet. From Figure 6-17, we can see that Brian seems to have performed better than some students in his class. However, we still do not know exactly how much better he did. To find out the exact percentile rank, we need to use a z table, as shown in Figure 6-18. Steps in using the z table to find a corresponding percentile rank are summarized in the box that follows.
Brian’s z-score.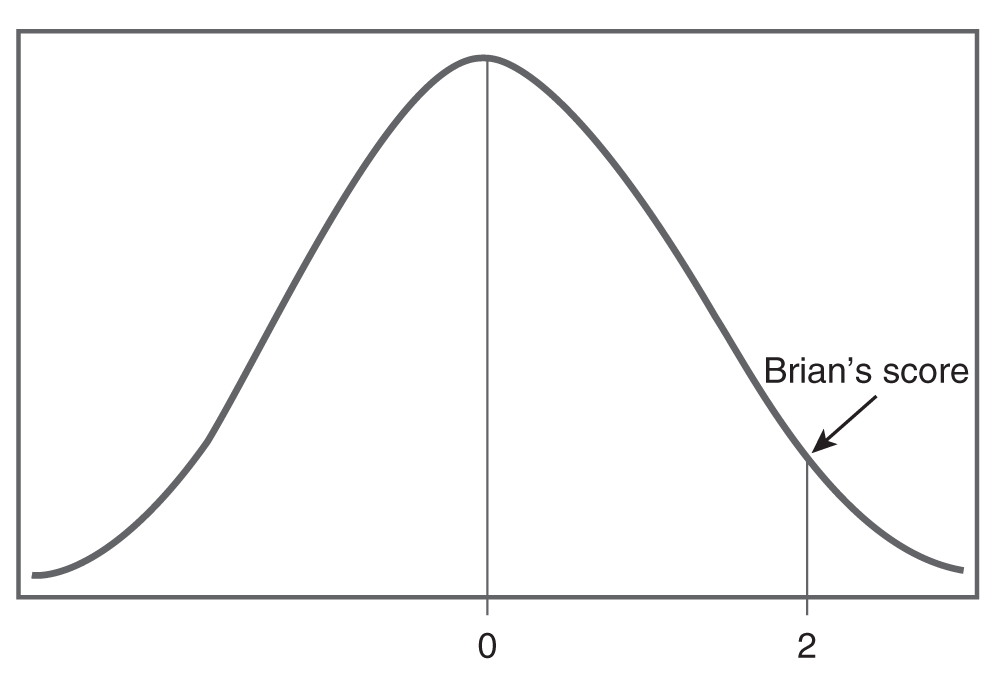
A normal distribution curve with mean 0, shows the Brian's score of 2.
z table.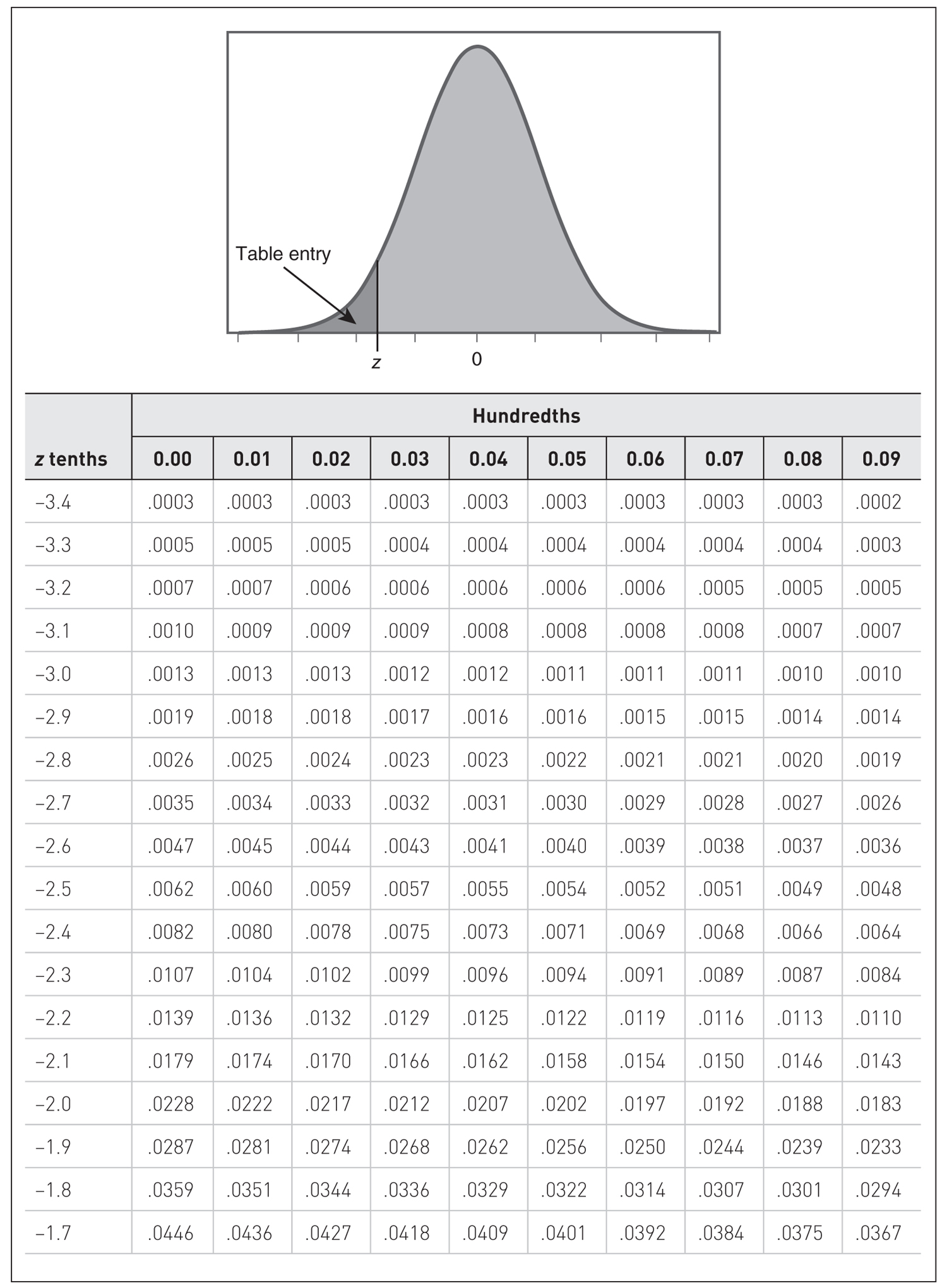
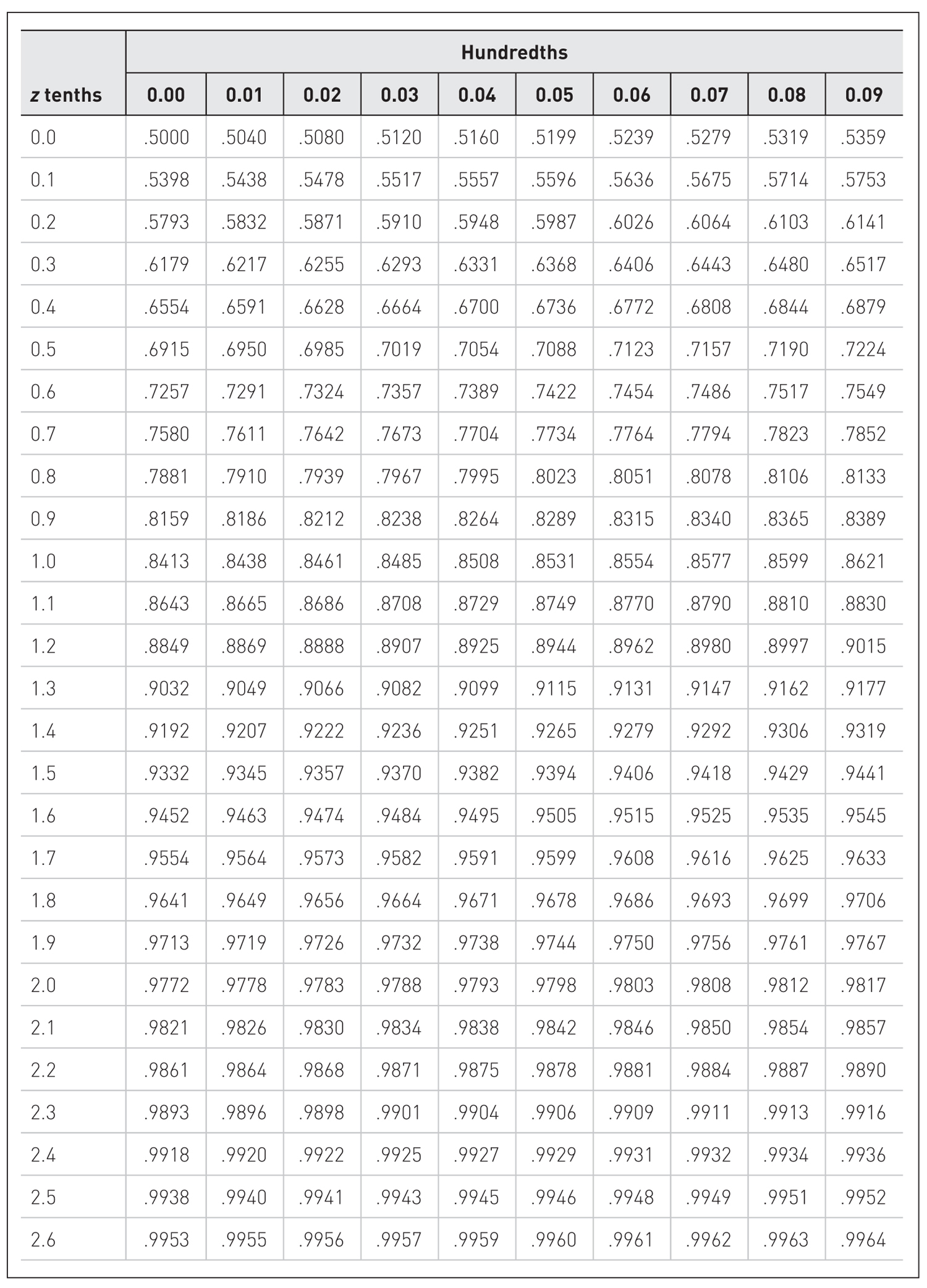
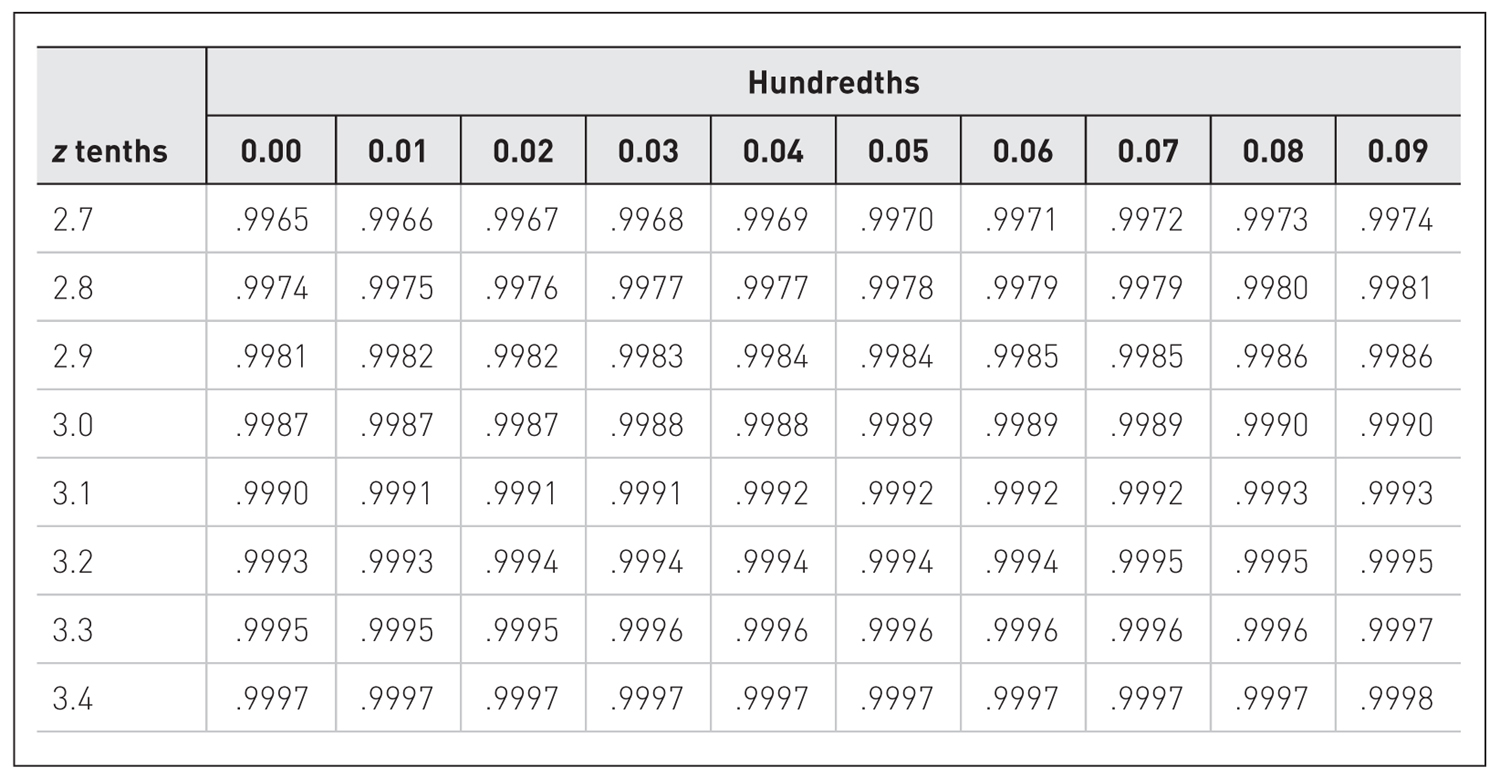
A figure shows a normal distribution curve accompanied by z table.
Using the z Table to Find a Corresponding Percentile Rank of a ScoreConvert Brian’s final exam score to a corresponding z-score.
- Locate the row in the z table for a z-score of +2.00. Note that the z-scores in the first column are shown to only the first decimal place. Also, locate the column for 0.00 so that you get 2.00 when you add 2.0 and 0.00.
- Brian’s z-score of +2.00 gives probabilities of 0.9772 to the left.
- Therefore, Brian’s final exam score of +2.00 corresponds to the 98th percentile. Brian did better than 98% of the students in the class.
|
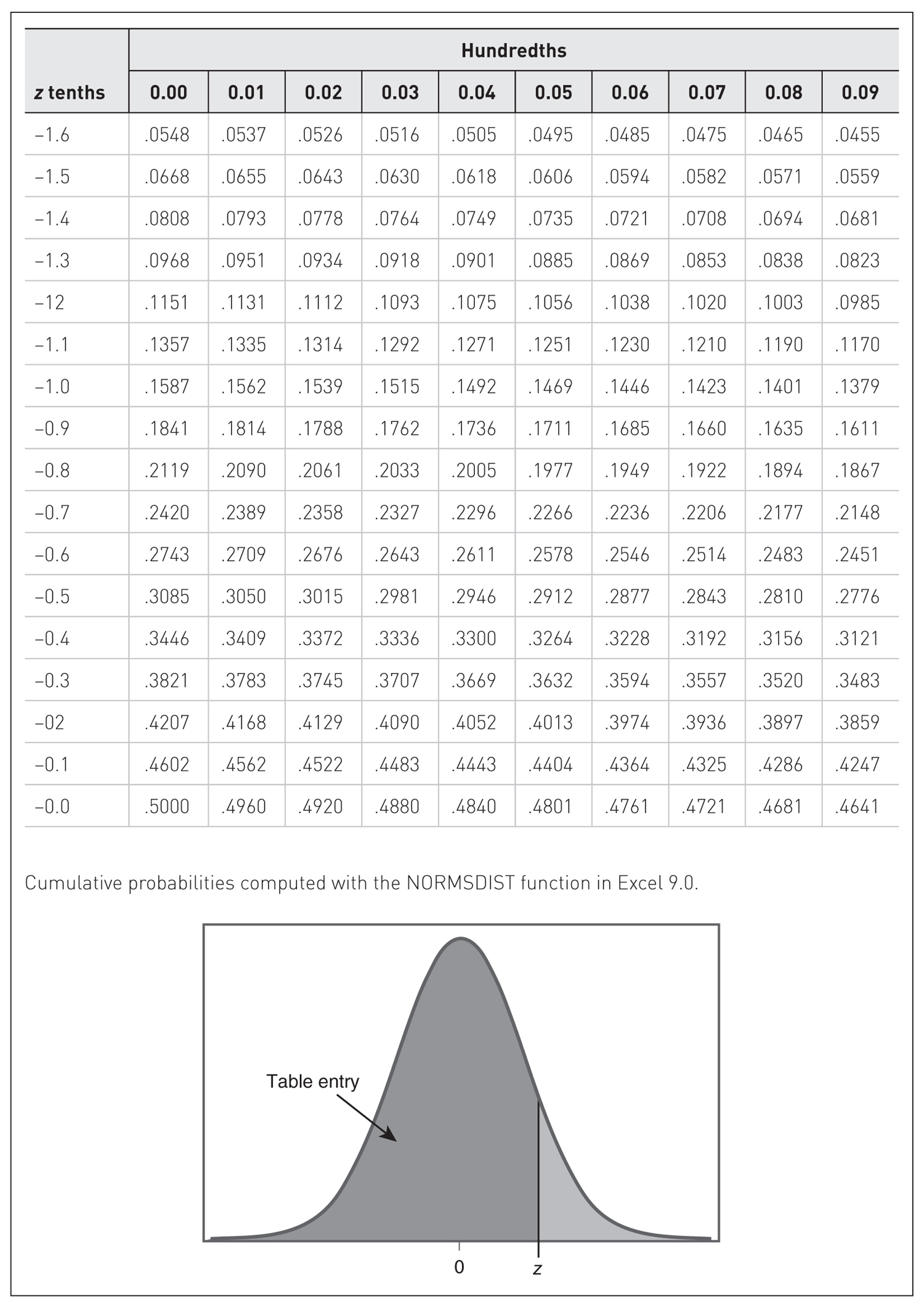
Let us consider another example that will help us understand how to find the corresponding probability for a given score. The sodium intakes for a group of cardiac rehabilitation patients are known to have a mean of 4,500 mg/day and a standard deviation of ±150 mg/day. Assuming that the sodium intake is normally distributed, let us find the probability that a randomly selected patient will have a sodium intake level below 4,275 mg/day. First, we need to convert this value into the z-score. The corresponding z-score for 4,275 mg/day will be:
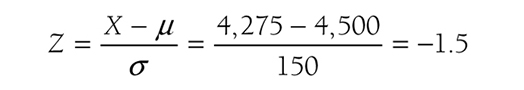
Locating the row in the z table for a z-score of -1.5 and the column for 0.00, you should get a probability of 0.0668. Therefore, the probability that a randomly selected patient will have a sodium intake below 4,275 mg/day will be 6.68%. How about the probability that a randomly selected patient will have between 4,350 mg/day and 4,725 mg/day? Notice here that we have two scores to transform. The corresponding z-score of the lower level, 4,350 mg/day, will be:
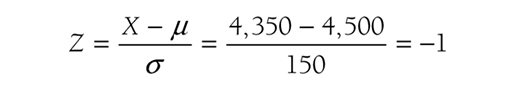
and the upper level, 4,725 mg/day, will be
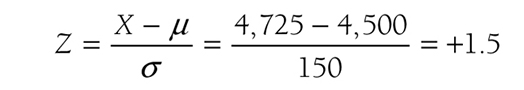
Therefore, we are looking at the area under the normal curve between -1 and +1.5 standard deviations, as shown in Figure 6-19. The probability to the left of +1.5 is 0.9332, and the probability to the left of -1 is 0.1587. To get the probability between -1 and +1.5, we will subtract 0.1587 from 0.9332 and should get 0.7745. Therefore, the probability that a randomly selected patient will have a sodium intake between 4,350 mg/day and 4,725 mg/day will be 77.45%. Finding the corresponding probabilities for a given score can be tricky, so we recommend that you work on as many examples as you can, including what is provided at the end of this chapter.
The normal curve between -1 and +1.5 standard deviations.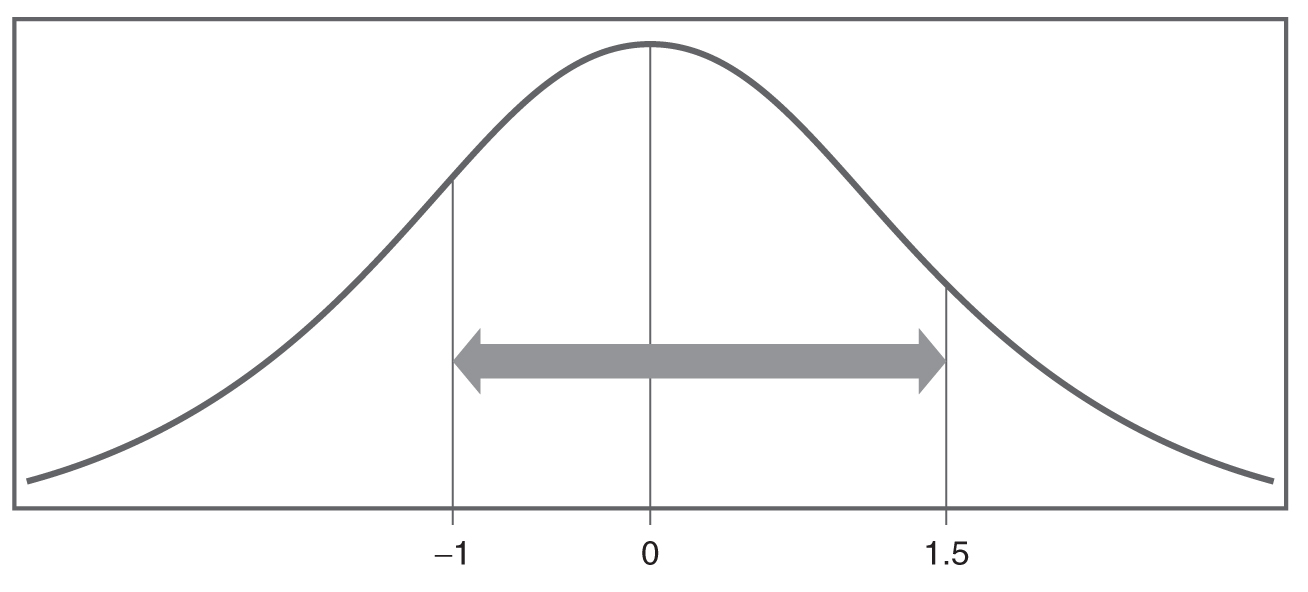
A standard normal distribution curve is shown between the standard deviations, minus 1 and plus 1.5, from the mean.
As a closing note about the standard normal distribution, recall that the following are true when a variable is normally distributed:
- 68% of observations fall within one standard deviation from the mean in both directions.
- 95% of observations fall within two standard deviations from the mean in both directions.
- 99.7% of observations fall within three standard deviations from the mean in both directions.
This means that 68% of the z-scores will fall between -1 and +1, 95% of the z-scores will fall between -2 and +2, and 99.7% of the z-scores will fall between -3 and +3, because the standard normal distribution has a mean of 0 and a standard deviation of 1. This is important because any z-score that is greater than +3 or less than -3 can be treated as unusual.